Fail-over overview
This solution is based on Streaming replication that allows a database server to send a stream of data modifications to another server. PostgreSQL physical replication constructs a stream of logical data modifications from the WAL (write ahead log) and allows the data changes from individual tables to be replicated. In case of primary database fails, the standby database could be promoted to primary, as depicted below. This fail-over functionality could be either manual or automatic.
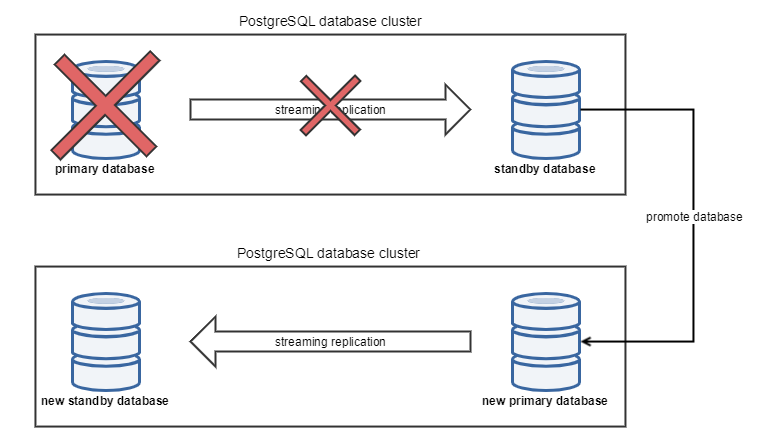
Manual fail-over
- Check if the primary database is accepting connections by running command below.
'pg_isready.exe' is utility in '<PATH_TO_PRIMARY_DATABASE_ROOT_FOLDER>\bin' folder. The command can be run from any computer with network visibility to primary database.
pg_isready executionpg_isready.exe --host=<PRIMARY_DATABASE_IP> --port=<PRIMARY_DB_PORT> --username=<ALLOWED_USERNAME> --timeout=<timeout_in_seconds>pg_isready with real valuespg_isready.exe --host=10.0.124.110 --port=5433 --username=replicator --timeout=60
- Promote 'stand-by' database.
- Connect to the computer with standby database.
- Change directory to '<PATH_TO_STANDBY_DATABASE_ROOT_FOLDER>\bin' folder if you don't have it on a PATH.
Run the command below to promote database to the primary (usual value of '<PATH_TO_STANDBY_DATABASE_DATA_FOLDER>' eg 'C:\Program Files\PostgreSQL\16\data').
pg_ctl.exe promote -D <path_to_postgres_data_folder>
- Check if the newly promoted database is primary.
Check if the newly promoted database is primary by executing query below on a newly promoted database. Result should be false.
selectpg_is_in_recovery()- Check the management interface authentication works. You should be able to log in and use the interface for administrative tasks.
Automated monitoring and Fail-over
Automated fail-over is based on checking primary database from the server with the stand-by database in periodic intervals and automatically promote stand-by database if the primary database is down. In this setup, we will use the Windows schedule task to invoke PowerShell script that follow the same steps as described in Manual fail-over section.
Script location
Script are located in the full installation package <installation package>\Complementary Solutions/PostgreSQL/pg-failover.zip
- On the server with stand-by database, add PostrgreSQL CLI utilities to PATH system environment variable.
- Dispatcher Paragon with embedded PostreSQL has CLI tools at '<PATH_TO_STANDBY_DATABASE_ROOT_FOLDER>\bin' folder. Default installation path of PostgreSQL CLI utilities is C:\Program Files\PostgreSQL\16\bin .
- Copy the PowerShell script PgPromote.ps1 to server with stand-by database.
- On the server with stand-by database:
- Create a new scheduled task in the Task Scheduler.
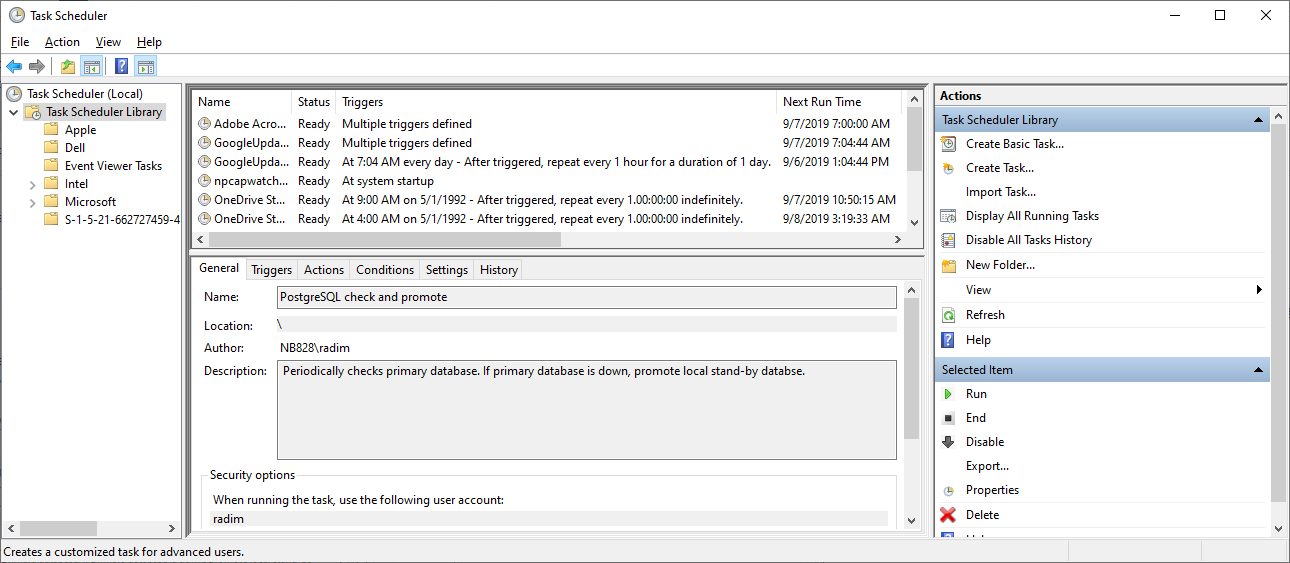
- In "General" tab, fill the name, description, check "Run whether user is logged on or not" and "Run with highest privileges".
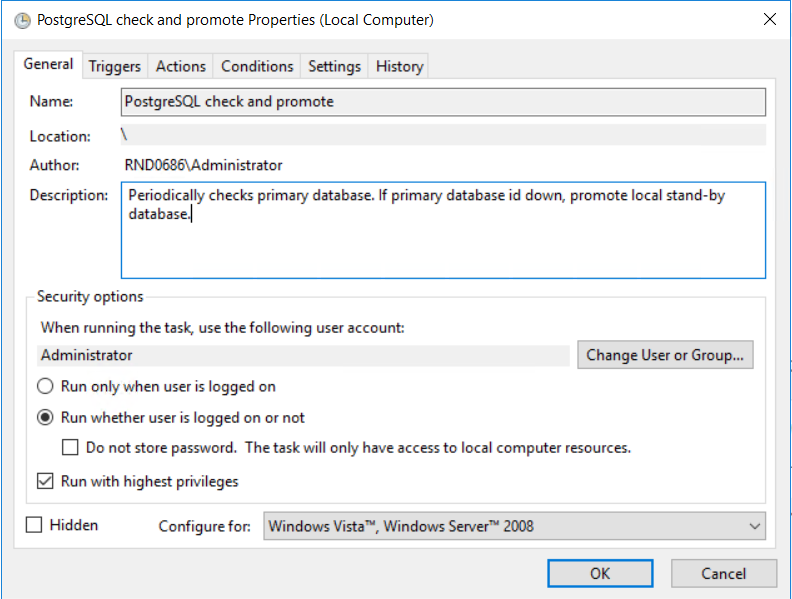
In "Triggers" tab, create new trigger, that will run every minute and never expires.
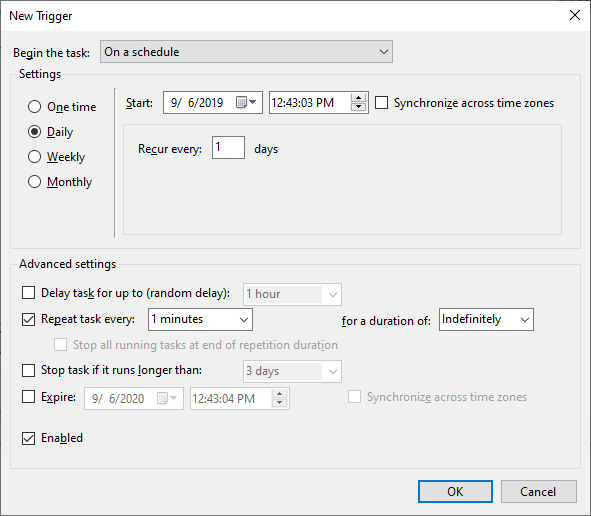
Windows Server 2019
If you use Windows Server 2019, you have to change this settings to "One Time" instead of "Daily" and under the Advanced settings set Repeat task duration to "Indefinitely"
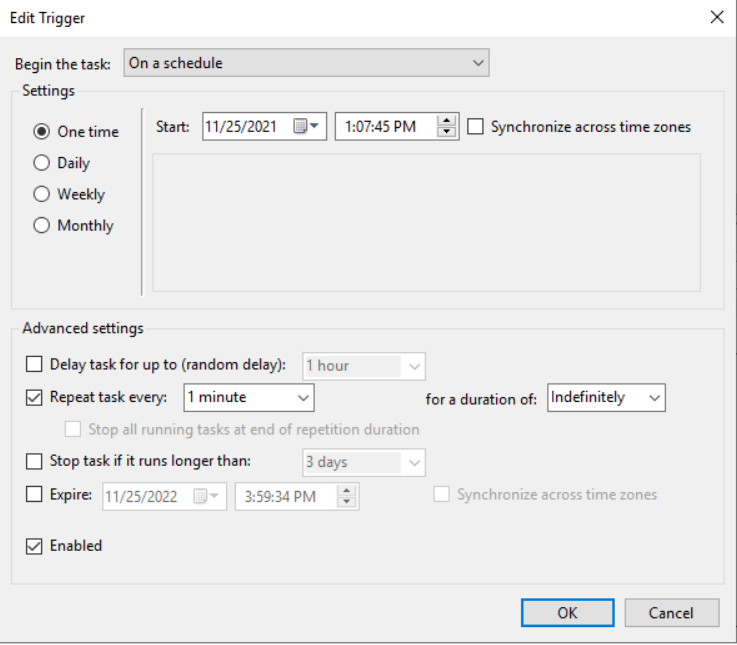
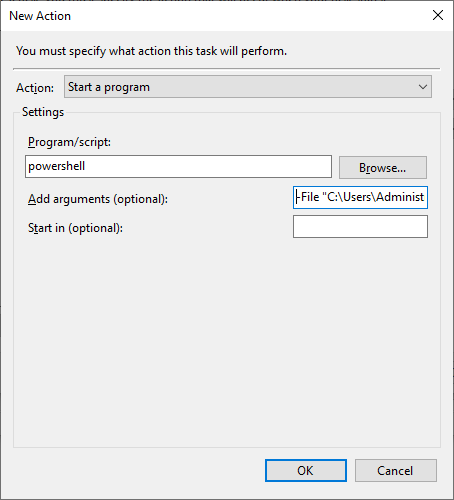
In the "Actions" tab, create a new action that will start a script. Use Powershell as program to start and add following arguments.
-File"<path_to_script>\PgPromote.ps1"-masterAddress <PRIMARY_DATABASE_IP_ADDRESS> -port <PORT_OF_PRIMARY_DATABASE> -username <ALLOWED_USERNAME> -path"<PATH_TO_STANDBY_DATABASE_DATA_FOLDER>"<ALLOWED_USERNAME> is replicator user allowed in pg_hba.conf.
- Create a new scheduled task in the Task Scheduler.
- Save the scheduled task and trigger it manually to ensure it will run every one minute. Wait one minute so the scheduled task runs at least once and check Windows Event Application log for errors.
(Optional) if you are not sure if the script is invoked correctly, you can turn on logging by add log parameter to turn logging on. Example: -log "C:\logs\PgWatcher.log"
-File"<path_to_script>\PgPromote.ps1"-masterAddress <PRIMARY_DATABASE_IP_ADDRESS> -port <port_of_primary_DB> -username <ALLOWED_USERNAME> -path"<PATH_TO_STANDBY_DATABASE_DATA_FOLDER>"-log"<PATH_TO_LOG_FILE>"In case of planned server outage, please consider disabling the fail-over script to avoid the need to do the manual recovery afterwards.
Notifications
When automatic fail-over script detects that standby database is down, it logs a Warning Windows event in Event Log.
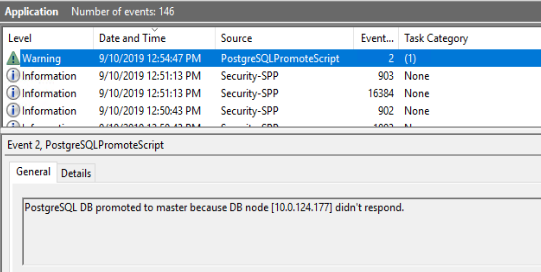
Automatic fail-over script logs the following events to the Windows Event Log.
EventID | Title | Description | Level | Source |
|---|---|---|---|---|
1 | Environment check failed | Some of the PostgreSQL CLI utilities were not found on PATH or path of PostgreSQL folder doesn't exists. See the error message which tells you what happen. | Error | PostgreSQLPromoteScript |
2 | Stand-by database promoted to primary | The primary database went down, stand-by database was promoted. | Warning | PostgreSQLPromoteScript |
Recommended
It is recommend to add custom action on the event ID 2, (for example to send an email to the administrators) to avoid data loss or data inconsistency. Please refer to Caveats section below.
Recovery scenarios
Based on the role of the failed database, either one of the options is available:
- in case of failed primary database, the remaining standby database has all the data since the failure, so it could be promoted to primary database and failed previous primary has to be recovered as future standby
- in case of failed standby database, either reconnect the database and let the replication replay all the changes or recover the database from scratch
The below sections describe both scenarios in greater detail.
Recover failed standby database server
In case the standby database server fails, primary database server is still serving the application.
Primary database is still recording the transaction in WAL files, but only for a limited time (depending on the configuration option wal_keep_segments, refer to the PostgreSQL cluster). Until the number of WAL files does not reach the wal_keep_segments, the state of the standby database could be still replayed from these backups - we refer to this as Temporary connection outage. In the other case, when the WAL files max count is reached, the primary database starts to reusing the WAL files starting from the older ones and the automatic replay is not an option anymore. This is considered as Long term connection outage and different solution has to be applied.
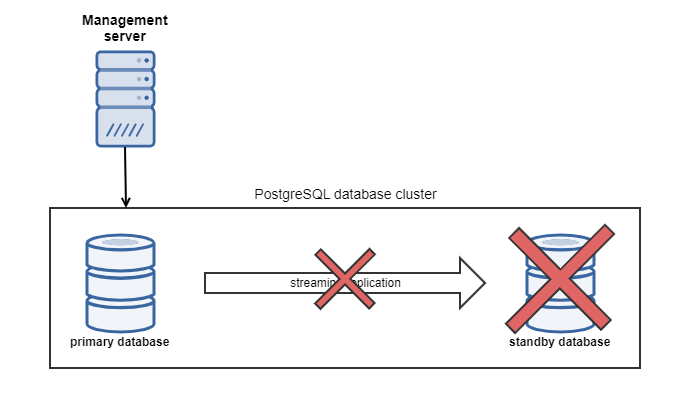
Temporary connection outage to the standby database
In case of temporal connection outage, the standby database will "catch up" with the primary database as soon as the connection is established, replaying all the changes done in primary database since the last synchronization. To verify that, the similar log messages should be found in the standby log files:
LOG: entering standby modeLOG: redo starts at 0/B000E20LOG: consistent recovery state reached at 0/B000F00LOG: database system is ready to accept read only connectionsPlease note, that time for which the standby database could be offline is limited. The maximum time, for which all the changes done in primary database will be automatically replayed on standby is determined by the wal_keep_segments configuration option (refer to PostgreSQL cluster for more details). If the standby database is taken online after the primary database starts reusing the following error message will appear in standby's database log file and the replication fails. In such case, do the entire database restore as described below.
FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 00000002000000000000000B has already been removedLong term connection outage to the standby database
If the standby database is offline while the primary database's count of WAL files reached its maximum and starts reusing the earlier WAL files, the recovery via streaming replication is no longer available due to missing data. In such case, the standby server data has to be recreated again in the same way as when configuring the standby database for the first time (refer to PostgreSQL cluster).
- Stop the database service YSoftPGSQL (if not stopped already due to failure).
- Backup the content of the data folder. In case of embedded database installation, the folder is located in
C:\<dispatcher_paragon_folder>\Management\PGSQL-data. - Delete the content of the data folder.
Run the following command, replacing the placeholders <...> with correct values a confirm with password.
<DB_IP_ADDRESS> - IP address of the primary database that will serve as source of replication
<USER_NAME> - name of the database user that either has a superadmin role or user with REPLICATION option (refer to PostgreSQL cluster for user creation)
<DB_PORT> - database port for accepting incoming connections
<DATA_FOLDER_LOCATION> - location of the database's /data folder. This value may be omitted if it is set as the PGDATA environment variable.
pg_basebackup -h <DB_IP_ADDRESS> -U <USER_NAME> -p <DB_PORT> -D <DATA_FOLDER_LOCATION> -Xs -R -P -vAfter the command competition, verify the data folder is present and contains
recovery.donefile - this signals the recovery completion.- Remove the
recovery.donefile as well ascurrent_logfilesfile and the entirepg_logfolder. These files have been copied from the recovery source database and will only confuse readers. Start up the YSoftPGSQL service again. Verify that the most recent log file in the pg log file contains similar log messages:
LOG: redo starts at0/E000028LOG: consistent recovery state reached at0/E0000F8LOG: database system is ready to accept read only connectionsFATAL: the database system is starting upLOG: started streaming WAL from primary at0/F000000 on timeline2- Check if the automatic fail-over is setted automatically on the new Slave as described in section above.
Recover failed primary database server
In case of the primary database server fails, the administrator is notified about standby database promotion by event in Windows event log on (see Notifications in Automated Failover section). Standby database is promoted to be new primary database, but the previous primary database has to be manually recovered to become part of the cluster again - now in the role of standby. In other words, database that was a standby had been promoted to primary, and database that was primary has to be recovered to be a standby.
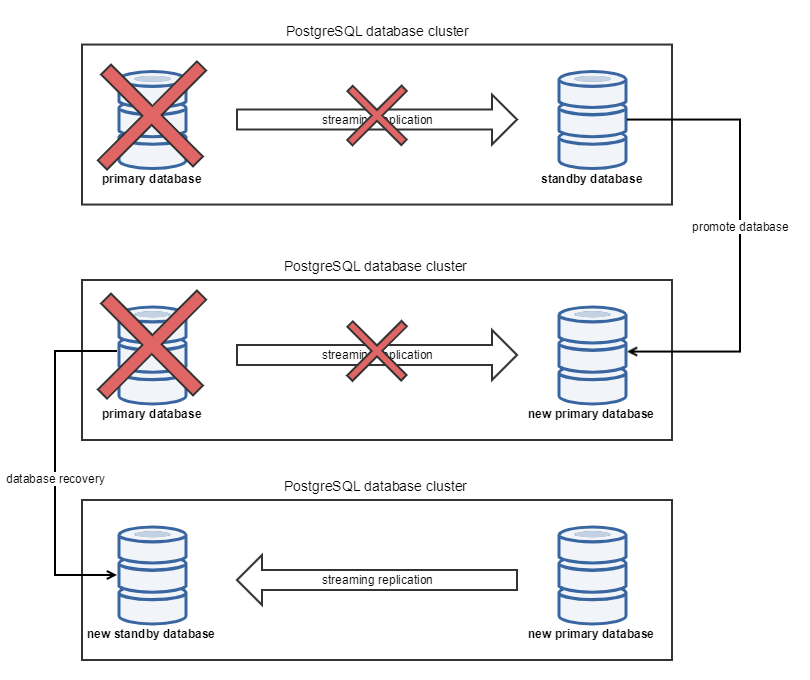
The recover operation will replay all the data from the current primary database, and enabling the standby mode. To apply this, follow these steps:
- Stop the database service YSoftPGSQL (if not stopped already due to the failure).
- Backup the content of the data folder. In case of embedded database installation, the folder is located in
C:\<dispatcher_paragon_folder>\Management\PGSQL-data. - Delete the content of the data folder.
Run the following command, replacing the placeholders <...> with correct values a confirm with password.
<DB_IP_ADDRESS> - IP address of the primary database that will serve as source of replication
<USER_NAME> - name of the database user that either has a superadmin role or user with REPLICATION option (refer to PostgreSQL cluster for user creation)
<DB_PORT> - database port for accepting incoming connections
<DATA_FOLDER_LOCATION> - location of the database's /data folder. This value may be omitted if is set as the PGDATA environment variable.
pg_basebackup -h <DB_IP_ADDRESS> -U <USER_NAME> -p <DB_PORT> -D <DATA_FOLDER_LOCATION> -Xs -R -P -v
After the command competition, verify the data folder is present and contains
recovery.donefile - this signals the recovery completion.- Remove the
recovery.donefile as well ascurrent_logffilesfile and the entirepg_logfolder. These files have been copied from the recovery source database and will only confuse readers. Start up the YSoftPGSQL service again. Verify that the most recent log file in data folder /pg_logs contains this log message.
LOG: database system is ready to accept read only connectionsDatabase will accept only read only connections - meaning this database is in hot-standby mode - all data changes done in primary database are immediately replicated into this hot-standby database, but only read only queries could be executed there.
Do not forget
Once the previously failed primary database is recovered as standby database, do not forget to setup automatic fail-over as described in section above.
Fail-over and Recovery caveats
Please be aware about the following limitations of the solution.
Avoid having two primary databases
In case of promoting standby database to primary due to failed primary database (either automatically or manually), it is vital not to start failed primary database. Having two primary databases up and running will lead to data inconsistency, because primary databases does not replicate data between themselves.
To mitigate this issue, always have PostgreSQL service Startup type set to Manual, as described in configuration section
Recommendation
It is recommended to check the status of failed primary database whenever the fail-over notification is received and do the recovery steps in order to minimize potential data loss or data inconsistency. For notification setup, please refer to Automated fail-over Notifications section above, for monitoring databases, refer to PostgreSQL cluster monitoring.
Delay between promoting standby server to primary
Even with the automatic fail-over script in place, there is some time (currently limited to 90 seconds) for which the primary database is down and standby database is serving read-only requests. For this period, the following happens:
- any request made to the running standby server with read only queries will be handled
- any request made to the running standby database server with read/writes queries will be rejected
- any request made to Management server with read/writes queries will be rejected
- any request made to Management server GUI will be served with the HTTP 500 response status