Overview
Dispatcher Paragon Data Mart Mode (DMM) is a function for collecting and transforming print-related data to make it available for further online analytical processing (OLAP) and data mining functionality for business intelligence applications. From a high-level perspective, it can be divided into three layers:
- Data source
- Data mart
- Data presentation
With the support of multitenancy, each tenant database scheme represents a standalone data source. These data sources are transformed into a tenant's data marts – a tenant's warehousing data. A data mart is a collection of all a tenant's data marts.
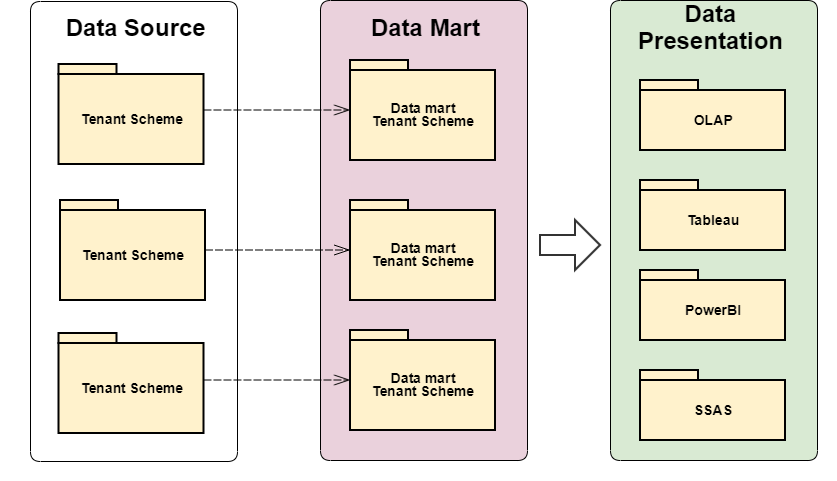
Data mart
Data mart is taking care of already transformed data from a data source that will be used for further presentation. Data in a data mart is referenced as statistics. There are two different types of statistics storage. The first is designed for Web Reports presentation and data is referenced as web reports. The second is designed for business intelligence (BI) engines and data is referenced as SQL API.
Each tenant's data mart has its own, specific credentials (the tenant_warehouses table in the cluster_mngmt schema).
Data presentation
Covers various means of presenting and visualizing the generated statistics.
- Built in Management Service Web Reports with predefined filters.
- External reporting system connected to data mart via SQL API (e.g., Power BI).
- External data warehouses connected to data mart via SQL API.
Data Life-cycle
Statistics are computed either in regular intervals or explicitly on a user's demand (see the Action option in the Web Reports section). The basic sources for the statistics are accounted jobs placed in the tenant schema.
In the case of a multi-node Management service deployment, only one statistics recalculation is executed at a time.
The ETL (extract, transform, load) process that computes statistics is placed in the database. In a high-level overview, the computation steps of ETL are as follows:
- Compute statistics:
- Web reports
- Management reports
- Counter reports
- Generate data mart data (SQL_API dimensions and measurements)
- Delete old statistics based on the configuration
Configuration
Statistics computation is done every hour (configurable using the smallStatisticsRecalculationSyncJobCronRule property ) – this is so-called "small statistics". In addition, every day at 1:00 AM (configurable using the fullStatisticsRecalculationSyncJobCronRule property) the "full statistics" computation is executed, which also removes expired jobs.
By default, data mart statistics computation is turned off.
For enabling data mart statistics computation, use the configuration property enableCMLDataMart. Similarly, use the web-stats-enable property for web reports, enableManagementReport for management reports and enable-purge_reports for Green reports.
Use the following properties to fine-tune statistics data retention:
- maxStatsMonthsBase – The maximum number of months for which web reports and counter reports data are stored. The default value is 36.
- maxStatsDaysFull – The maximum number of days for which unaggregated web reports are kept. The default value is 31.
- maximumCMLDataMartMonths – The maximum number of months for which the data mart measurements are kept. The default value is 36.
- remove-jobs-from-db – The maximum number of days after which the print jobs' metadata will be removed (along with the jobs log and jobs accounting metadata). The default value is 31.
printJobAgeForStats – The minimum age of print jobs to include in web reports and data mart statistics for the Management Service cluster environment, in minutes. If the value is higher than 120 or lower than 10, it will default to 20.
Data Mart in Detail
The Dispatcher Paragon data mart uses the star schema described in the next section, SQL API model description. That means each dimension table is directly connected to a fact table (measurement table). It is located in the main SQDB6 database in the dwhtenant_%i% schema where the %i% is replaced with the tenant scheme sequence number. All tables in the data mart are prefixed with the "dm_v2_" keyword, where v2 means api version number 2. This allows for easy filtering in the analytics software.
In a single-tenant environment, the database schema's name is dwhtenant_1.
Fact tables in the Dispatcher Paragon data mart are suffixed with the "_measures" keyword. Fact tables contain the main data to be analyzed with the cube analytic software. Dimension tables in the Dispatcher Paragon data mart are suffixed with the "_dimension" keyword. Dimension tables contain data to be used as axes of the cube or to filter by. A description of all the fact and dimension tables is in the next section.
Interconnection of measurement tables with dimension tables is done through foreign key references. Data in the dimension tables is referenced by its primary key ID field from the fact tables. Columns in the fact table that reference a row in the dimension table are suffixed with the "_dimension_id" keyword.
Dimension table naming and references to dimension tables
Having a dimension table devices, the table would be named dm_v2_device_dimension and the reference to a device from a fact table is made via the column with name device_dimension_id in the fact table. There is also a foreign constraint present on this column in the fact table that points to the ID column of the dm_v2_device_dimension table.
This interconnection of fact tables with dimension tables through foreign key constraints allows the analytical software (like Power BI) to automatically build the structure of the data mart. This way, the user of the SQL API does not have to interconnect the tables manually.
Entities
There are three fact tables in the Dispatcher Paragon data mart, all of which use several dimension tables. Some dimension tables are not active at the moment so they contain only one row with an UNKNOWN value and every row in the fact table references this UNKNOWN value.
Fact tables
Fact Table Name | Description | State |
|---|---|---|
dm_v2_print_accounting_measures | This fact table contains accounting information about jobs. One job can have multiple items of accounting information. | populated |
dm_v2_print_job_measures | This fact table contains details about jobs (date of printing, page count, sheet count, device used for printing, etc.). | populated |
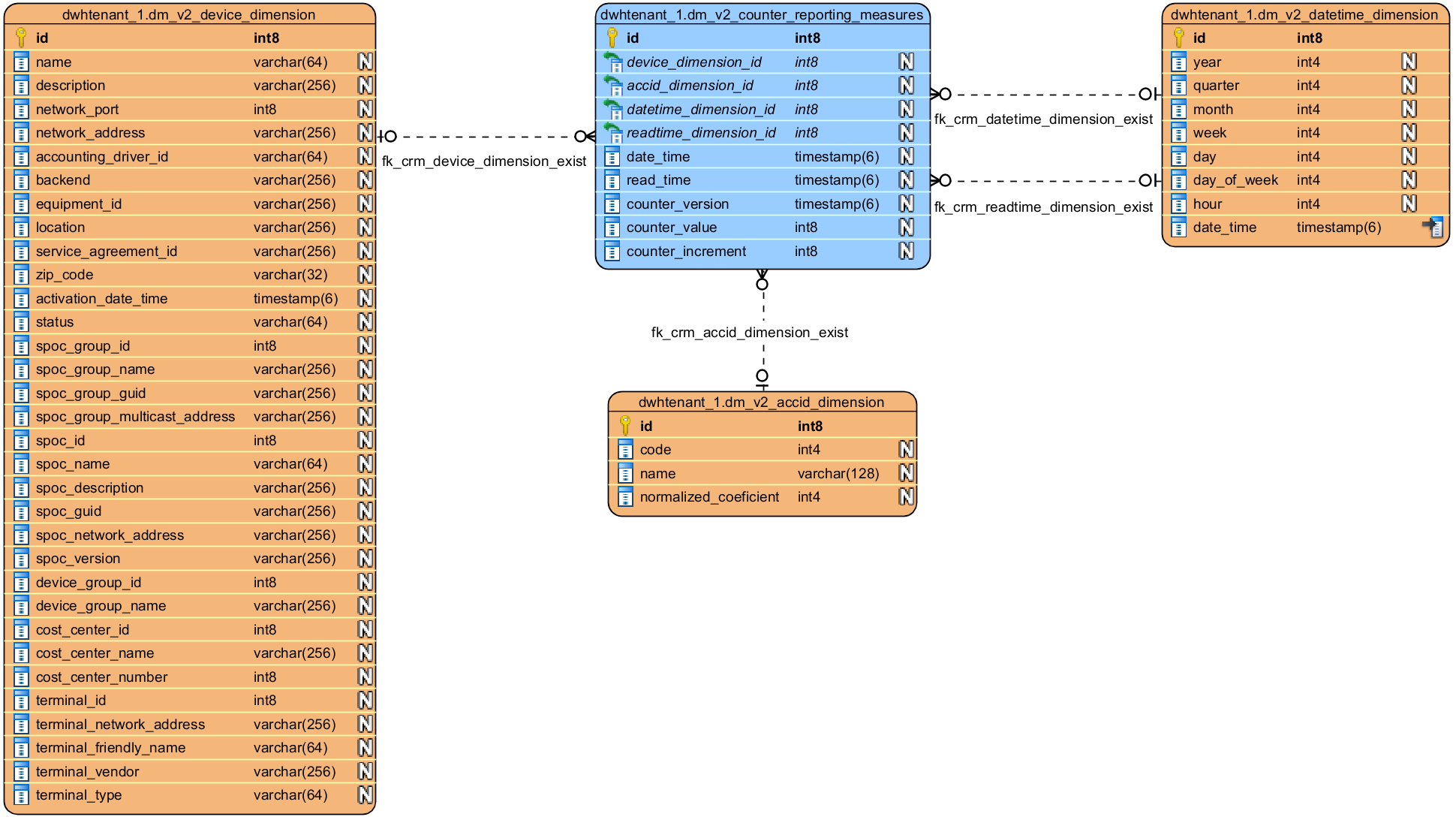
dm_v2_counter_reporting_measures | This fact table contains counter reports of all devices (one record per device and counter type per day). | populated |
Measurement tables
Measurement Table Name | Description | State |
|---|---|---|
dm_v2_accid_dimension | Device counters indicate the total number of pages printed on a given device, e.g. A4BW. (see Counter reports for more information about counters) | populated |
dm_v2_billing_code_dimension | Billing codes are selected when printing job on an MFP to group print jobs into projects. (see Management Interface - Billing) | populated |
dm_v2_color_coverage_dimension | Degree of color coverage (for custom-defined color levels based on rendered page images, e.g. ,<5%, 5-25%, 25-50%, 50-75%, >75%). | populated |
dm_v2_color_type_dimension | Type of color output [B&W, full color, Xerox 3-tier acctg levels, ...]. | populated |
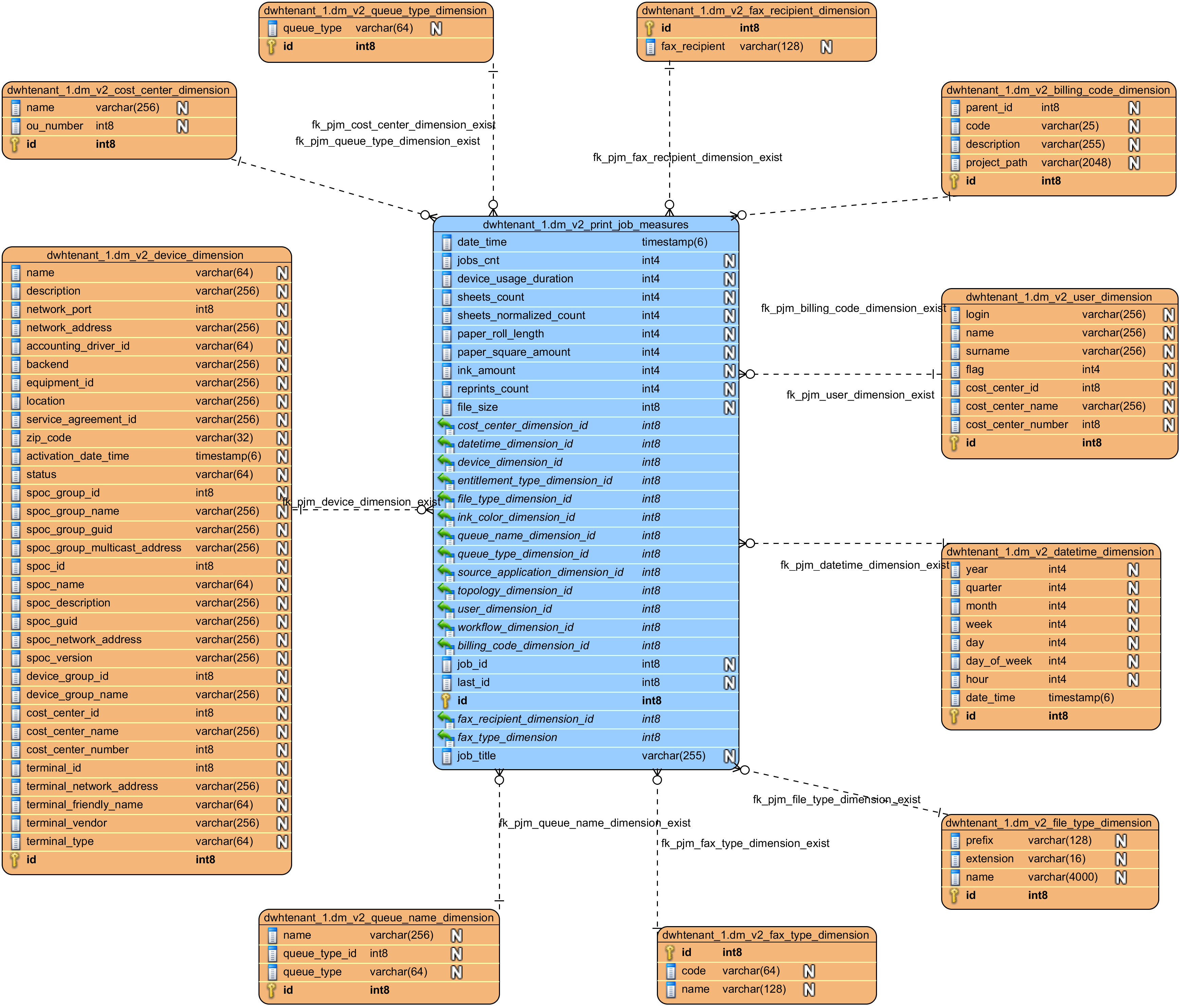
dm_v2_cost_center_dimension | A list of Accounting Cost Centers that are used. (see Managing Cost Centers) | populated |
dm_v2_datetime_dimension | Date and time (with at least a seconds granularity) to filter by. | populated |
dm_v2_device_dimension | A list of devices (dimensions representing various device attributes – name, cost center, location, device group, SPOC Group...). (see Management Interface - Devices) | populated |
dm_v2_entitlement_type_dimension | Entitlement type applied (none/quota/money). | unused |
dm_v2_fax_recipient_dimension | Fax recipient [email, fax number, ...]. | populated |
dm_v2_fax_type_dimension | Fax type [ip, internet, telephone, ...]. | populated |
dm_v2_filament_type_dimension | Filament type used for printing (ABS, PLA, HIPS, PVA). | unused |
dm_v2_file_type_dimension | File type printed. | populated |
dm_v2_finishing_type_dimension | Finishing type [none, stapling (corner, margin), hole punching, folding (half, Z, U), booklet, glue binding...]. | unused |
dm_v2_ink_color_dimension | Ink color (for plotters). | unused |
dm_v2_media_type_dimension | Media type (plain paper, thick paper, transparency...). | unused |
dm_v2_operation_type_dimension | Type of operation [print, copy, scan, fax send, fax receive, savings, 3D print]. | populated |
dm_v2_paper_format_dimension | Paper format (A5, A4, A3, Letter, Legal, Tabloid, Continuous...). | unused |
dm_v2_print_accounting_tag_junction | M-N table for tag_dimension and print_accounting_measures mapping. | populated |
dm_v2_queue_name_dimension | Specific queue name a job was sent to. | populated |
dm_v2_queue_type_dimension | Type of queue a job was sent to [secure/direct/shared]. | populated |
dm_v2_rbe_action_dimension | Applied RBE action(s) forcing some printing behavior (force B&W, force duplex, force simplex, redirect, combinations). (See Defining a Rule in Rule-Based Engine) | unused |
dm_v2_savings_dimension | Savings cause [purge, force duplex, force B&W, redirect]. | populated |
dm_v2_sided_print_dimension | What sides of paper were printed to [Simplex/duple]. | populated |
dm_v2_source_application_dimension | Applications from which print jobs are sent. | unused |
dm_v2_tag_dimension | Tags/Label (both system and user tags... e.g., a report on the volume of mobile vs. non-mobile prints). | populated |
dm_v2_topology_dimension | Topology (originating computer, spooling computer, SPOC Group). | unused |
dm_v2_user_dimension | List of users (dimensions representing various user attributes – name, username, cost center...). (See Managing Users) | populated |
dm_v2_workflow_dimension | Workflows for scanning. This table contains the workflow name and the workflow connector name. (See Workflow Basics) | unused |
SQL API Model Description
SQL API is a database model of a data mart that enables developers to access reporting data in the data mart using SQL.
The data mart entity relationship diagram (ERD) is depicted below. Details are available in an SQL API whole model which is part of the reporting package in the <installation package>\Complementary Solutions path of the full installation package. The whole model is divided into two well-arranged parts.
Accounting measure group
In the accounting measure group, there are places' measures and dimensions related with job accounting, like pages count, price, filament usage, ...
Details are available in an SQL API accounting model file.

Job measure group
In the job measure group, there are places' measures and dimensions related with a job, like job size, jobs count, ...
Details are available in an SQL API job model.
Counter reporting group
In the counter reporting group, there are places' measures and dimensions related with a counter readouts, like date time representing counter reports for given day, read time of counter readout, counter version for device and increment of the counters....
Details are available in an SQL API counter model.