マージ

マージノード を使用して2つ以上のファイルを1つまたはそれ以上の出力ファイルに結合します。選択したフォームでグループ化、並べ替え、およびマージしてTIFFまたはPDFファイルに出力できます。
たとえば、マージノードでは次のサンプルワークフローが可能になります。
- Dispatcher Phoenixワークフローを介して、コニカミノルタ複合機、仮想プリンターキュー、またはその他のファイルからスキャンしたドキュメントを自動的にキャプチャします。
- シーケンシャルファイル名またはドキュメントメタデータに基づいてファイルを解析し、ファイルを1つのマージファイルに変換します。
- マージされたファイルを1つ、または複数の処理操作にルーティングします。
- 処理されたドキュメントを1つ、または複数の配信ノードにルーティングします(次を含みますがこれらに限定されません)。
注: マージノードを使用するワークフローには、ファイルをグループとして収集することができる収集ノードが必要です。収集ノードで [ファイルをグループとして処理] (一部のノードでは グループとして処理) フィールドのボックスをオンにしてください。ボックスを空白のままにするとマージ処理はファイルをマージすることができません。次の収集ノードはファイルをグループとして収集することができます。
マージノードを使用する
マージノードは次のファイル形式をサポートしています。
- HD Photo
- TIFF
- JPG
- GIF
- PNG
- BMP
- PDF (暗号化されたPDFファイルのマージはサポートしていません。)
マージノードは次の順序で操作を実行します。
- グループファイル
- グループ内のファイルを並べ替え
- 並べ替えされたグループのファイルをマージ
マージノードワークフローは出力ファイルの名前を生成します。以下の要素で構成されます。
- グループ内の最初のファイルの名前から拡張子(.JPG、.PNGなど)を引いたもの。
- そのファイル名に追加される増分カウンター番号。正常にマージされたファイルのグループごとに番号が自動的に増加します(例: report-1.tiff、somereport-2.tiffなど)。
マージ操作後にファイルサイズが変更される場合があり、ファイル数は必ずしもページ数と同一ではありません。
複数のページを含むファイルによってマージされた一部のファイルには他のファイルよりも多くのページが含まれます。同じページ数を確保するにはマージする前にファイルに対して 分割 処理を実行することをお勧めします。
マージノードは受信したファイルからドキュメントレベルとページレベルの メタデータ を組み合わせることができます。このようにワークフローでファイルを処理/ルーティングするためにメタデータを使用することができます(例: ファイルの名前変更、注釈付けなど)。
ワークフロー内の次のノードの処理制限に従ってマージの上限を設定する機能など、追加のマージオプションを使用することができます。
マージノードの構成
マージノードウィンドウを開くには、マージノードをワークフロー領域にドラッグアンドドロップしてダブルクリックします。次のタブを含むマージノードウィンドウが表示されます。
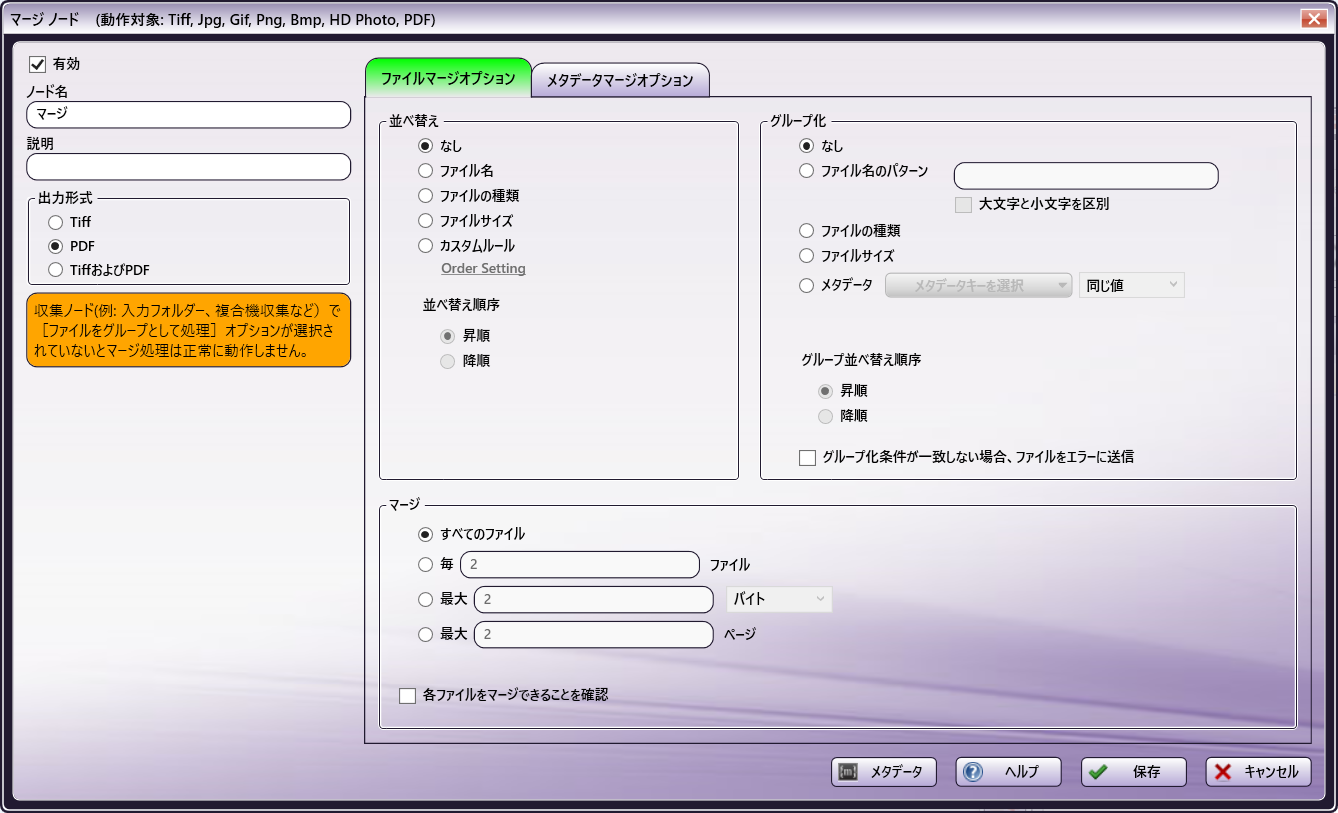
タブの左側に次のフィールドが表示されます。
-
[有効] - このマージノードをワークフローに含めるにはこのフィールドのチェックボックスをオンにします。チェックされていない場合、この処理は無視されます。ドキュメントはノードが存在しないかのように通過します。無効化されたノードはロジックまたはエラー状態をチェックしないことに注意してください。
-
[ノード名] - このマージノードに付ける、わかりやすい名前を入力します。
-
[説明] - このマージノードの説明を入力します。
-
[出力形式] - 出力されるマージドキュメントの形式を選択します。次のようなオプションがあります。
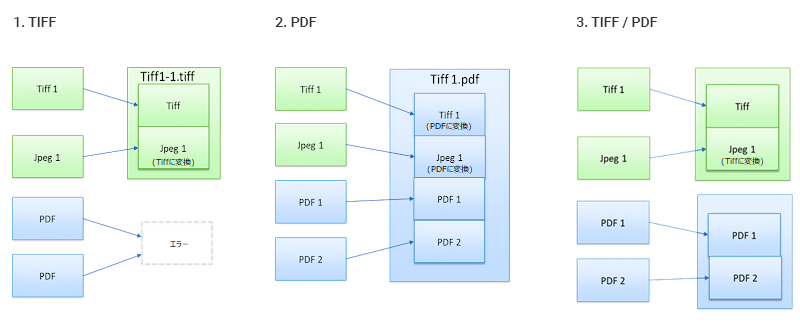
- [TIFF] - 複数の静止画像ファイルを単一のTIFFファイルにマージします。この形式はPDFファイルをサポートしていません。PDFファイルはエラーパスに送信されます。
- [PDF] - サポートされているファイルタイプをPDFに出力します。
- [TIFFおよびPDF] - サポートされているファイルタイプをTIFFまたはPDFに出力します。静止画像はマージされたTIFFファイルとして出力されます。PDFファイルはマージされたPDFファイルとして出力されます。
出力形式の図については次の図を参照してください。
マージノードウィンドウの下部に次のボタンが表示されます。
- [ヘルプ] - オンラインヘルプにアクセスします。
- [保存] - マージ定義を保持します。
- [キャンセル] - 変更を保存せずにウィンドウを終了します。
ファイルマージオプション タブ
このタブを使用してワークフローによって収集されたファイルの並べ替え、グループ化、およびマージの設定を指定します。
並べ替え
このパネルを使用してワークフロー内の直前の入力/処理ノードによって収集されたファイルをマージする順序を設定します。並べ替えする前に、マージは最初に指定したグループ化構成を適用することに注意してください。次の構成オプションがあります。
-
[なし] - ドキュメントを並べ替えない。
-
[ファイル名] - ファイル名でドキュメントを並べ替える。
-
[ファイルの種類] - ファイル種類または拡張しでドキュメントを並べ替える。
-
[ファイルサイズ] - ファイルサイズでドキュメントを並べ替える。
-
[カスタムルール] - メタデータを使用してマージ順序を制御します。 [カスタムルールで並べ替え] 画面で順序を構成します。詳細については以下の カスタムルール セクションを参照してください。
-
[並べ替え順序] - 上記のファイル属性フィールドのいずれかで並べ替えすることを選択するとこのフィールドがアクティブになり、次のオプションがあります。
- [昇順] - 最小値がリストの一番上になるようにファイルを並べ替える。
- [降順] - 最大値がリストの一番上になるようにファイルを並べ替える。
カスタムルール
メタデータを使用してマージの順序を構成するには、[並べ替え]パネルで[カスタムルール]を選択し、[順序設定(Order Setting)]をクリックします。 カスタムルールで並べ替え ウィンドウが表示されます。
カスタムルールで並べ替え ウィンドウを使用してマージの順序を決定するルールのテーブルを作成します。ルールを追加するには、ヘッダーバーの右側にある [+] ボタンをクリックします。

ルールがテーブルに表示されると次の構成オプションがあります。
-
[メタデータキー] - ドロップダウンをクリックしてメタデータブラウザーウィンドウにアクセスします。このウィンドウからメタデータキーを選択できます。
-
[並べ替え] - ソート順を指定します。次のオプションがあります。
- [昇順] - 最小メタデータ値が一番上になるようにファイルを並べ替えます(特殊 [#、$、など] -> 数値[0-9] -> アルファベット [A-Z])。同一のメタデータキーが複数のファイルに存在する場合、元のレコードの順序によって順序が定められます。
- [降順] - 最大メタデータ値が一番上になるようにファイルを並べ替えます(アルファベット[Z-A]->数値[9-0]->(特殊 [#、$、など])。同一のメタデータキーが複数のファイルに存在する場合、元のレコードの順序によって順序が定められます。
- [カスタムルール] - カスタムルール文字列を構成して並べ替え順序を決定します。このオプションを選択すると[ カスタムルール ]フィールドがアクティブになり、1つ以上のコンマ区切り値(CSV)で構成されるルールを指定できます。順序付けにより文字列がメタデータ値と比較されます。一致しないメタデータはすべて最後に並べられます。
-
[上/下に移動] - [上矢印] および [下矢印] ボタンを使用してカスタムルールの並べ替え順序を変更します。
-
[+] - この列の [+] ボタンと ボタンを使用してそれぞれルールを追加または削除します。ヘッダーバーの [+] ボタンは、リストの一番上に新しいルールを挿入します。
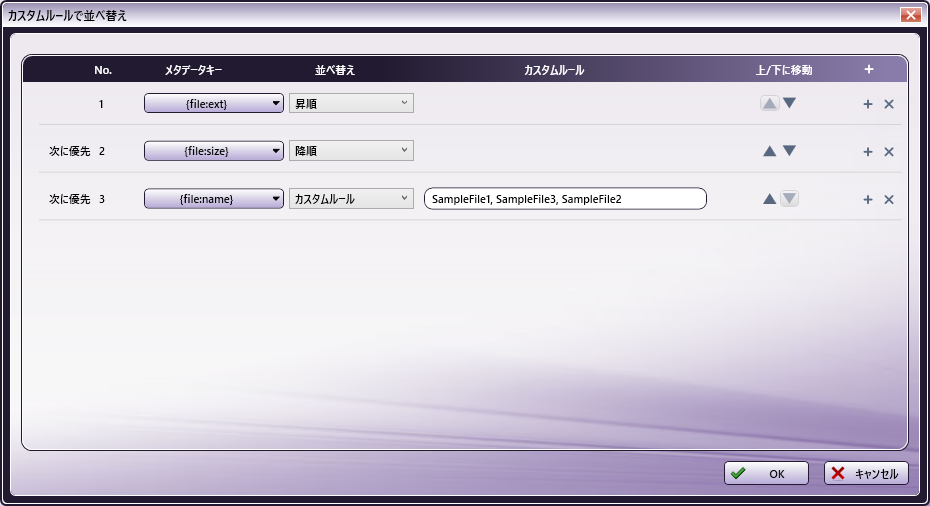
注: 複数のルールを操作する場合、最初のカスタムルールが実行されると、2番目のカスタムルールは最初のルールによって作成されたファイルの個々のグループごとに実行され、3番目のルールは2番目のルールによって作成されたファイルに対して実行されます。たとえば、ルール1がファイル拡張子でファイルを並べ替え、ルール2がファイル名で並べ替える場合、ルール2は、ファイルのグループ全体ではなく、同じファイル拡張子を持つファイルの各グループで実行されます。
グループ化
このパネルを使用してマージする前に収集されたファイルをグループに分割するための基準を指定します。ノードは構成によって作成されたグループごとにマージされたファイルを含む個別の出力ファイルを作成します。基準に一致しないファイルは「一致しない」グループに配置されます。
次の構成オプションがあります。
-
[なし] - ドキュメントを単一のグループとして処理します。
-
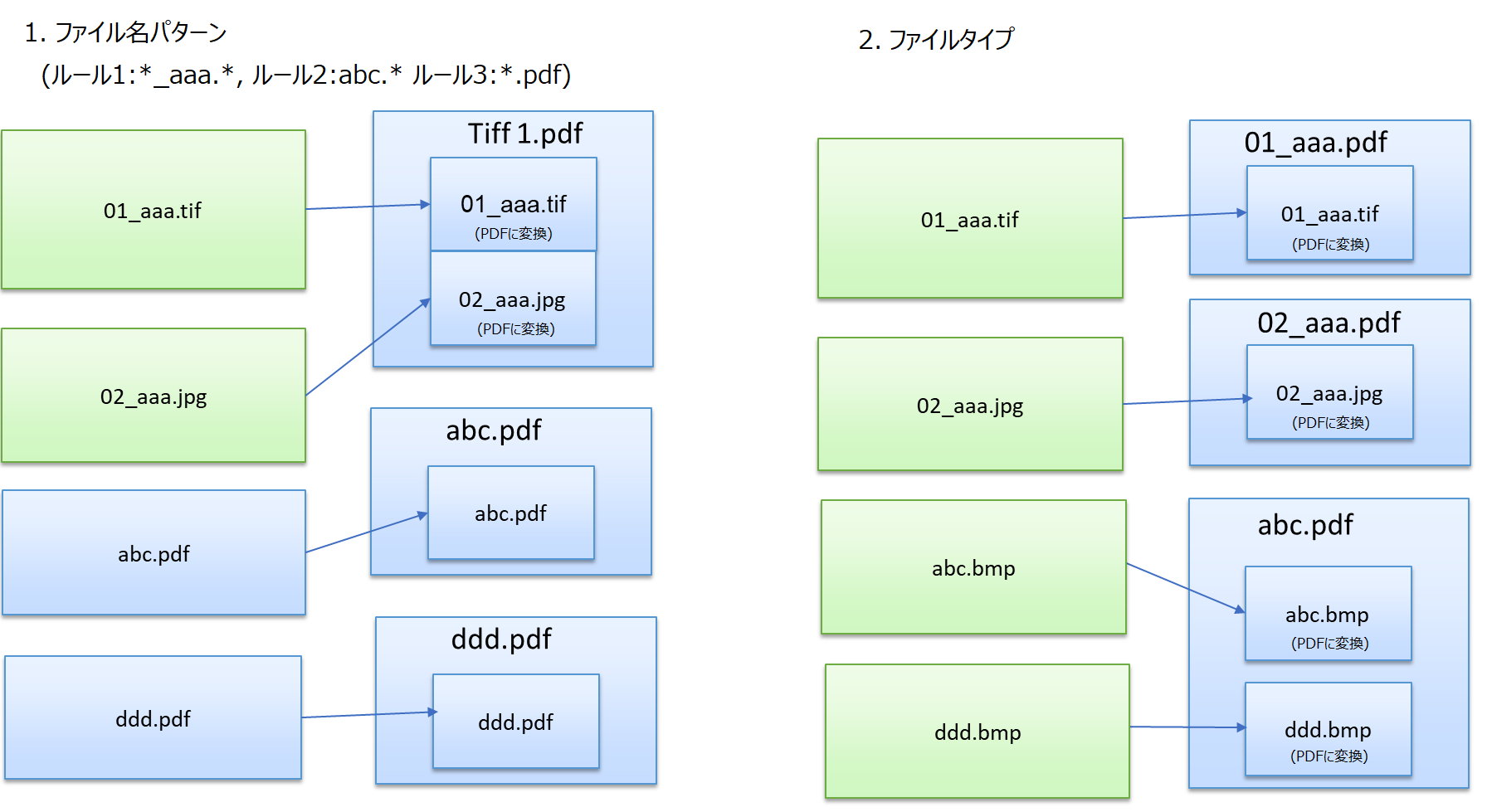
[ファイル名のパターン] - 命名規則を使用してファイルをグループ化します。このオプションを選択すると関連するフィールドがアクティブになり、1つ以上のコンマ区切り値(CSV)を入力してグループを識別できます。たとえば、次のようになります。
-
*_book.png
-
*.jpeg
- [大文字と小文字を区別] - [ファイル名のパターン] オプションを選択するとこのフィールドがアクティブになります。グループに追加する前に、CSV値をファイル名の大文字または小文字、あるいはその両方と一致させるにはチェックボックスをオンにします。それ以外の場合はボックスを空白のままにします。
-
-
[ファイルの種類] - ファイル拡張子でファイルをグループ化します。
-
[ファイルサイズ] - 元のファイルサイズを使用してファイルをグループ化します。
- 最小 (100KB未満)
- 中 (100KBから1MB)
- 大 (1MBから16MB)
- 最大 (16MB以上)
-
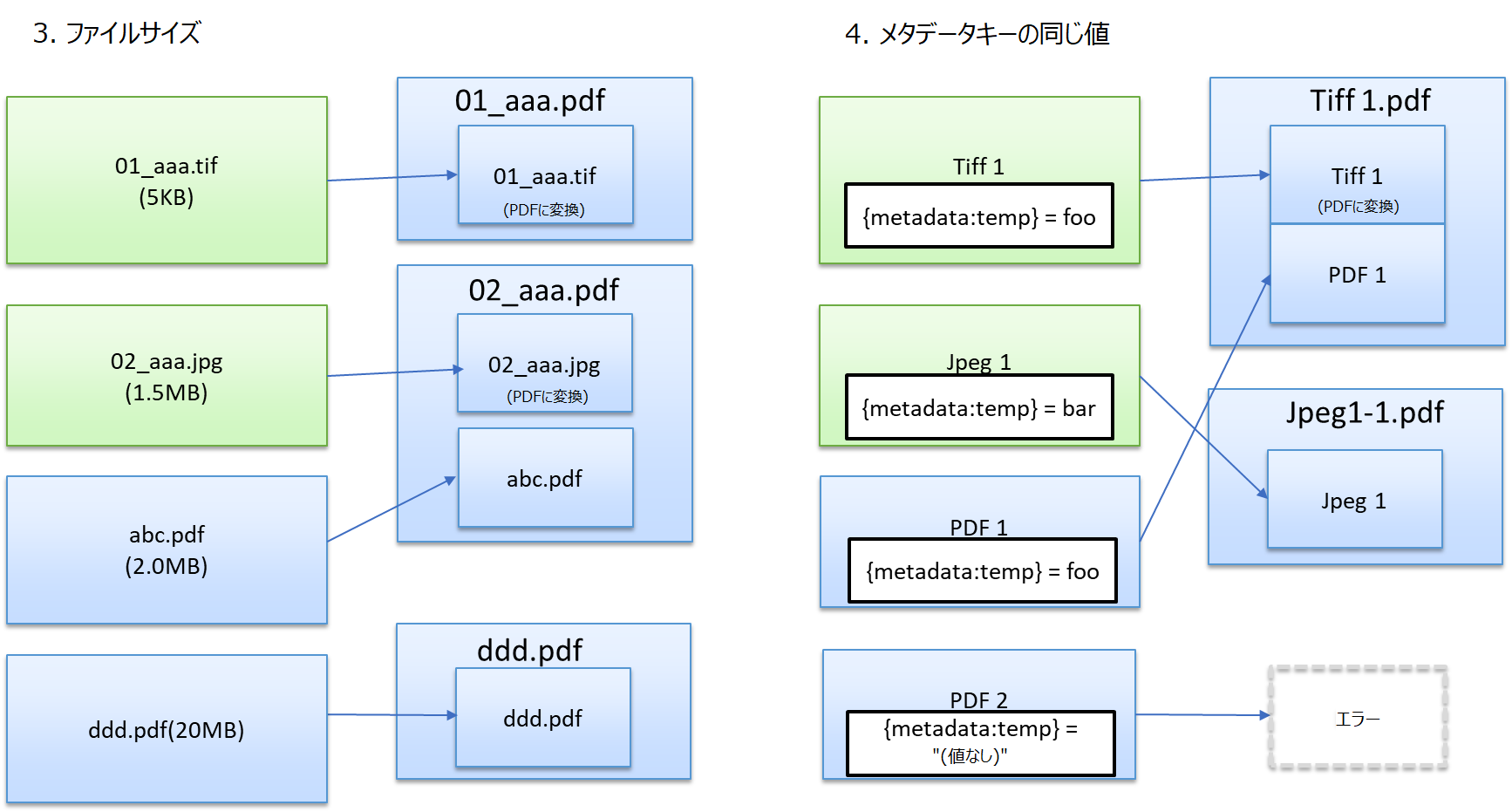
[メタデータ] - メタデータのキー値(ドキュメントおよびページレベル)を使用してメタデータ値でファイルをグループ化します。たとえば、同じ会社のすべての請求書でグループ化するように選択できます( OCR が必要です)。ドキュメントに複数の同一のメタデータキー値がある場合、このオプションは最初に見つかったものを使用します。
このオプションを選択すると [メタデータキーを選択] ボタンがアクティブになります。このボタンをクリックして メタデータブラウザーウィンドウ にアクセスします。このウィンドウでは、メタデータキーを選択してグループ基準を定めることができます。指定されたメタデータを含まないファイルはソートされたファイルリストの最後に配置されます。
メタデータキーを選択したら、右側のドロップダウンをクリックして [条件] を選択します。いくつかの条件では、検索条件を定義する 条件文字列 を入力する必要があります。次の条件のいずれかを選択できます。
- [同じ値] - 同じメタデータキーの値でグループ化する。
- [次の値] - 指定された条件文字列をメタデータ値に一致させてグループ化する。
- [次の値を含む] - 指定された条件文字列を含むメタデータ値でグループ化する。
- [正規表現] - メタデータ値を正規表現と照合してグループ化する。
- [存在する] - メタデータキーが存在する場合、ファイルをグループ化する。
- [を含む] - 指定されたメタデータキーに値がある場合、ファイルをグループ化する。
- [ではない] - 指定された条件文字列をメタデータ値に一致させずにグループ化する。
- [含まない] - 指定された条件文字列を含まないメタデータキーの値でファイルをグループ化する。
- [値なし] - メタデータキーに値がない場合、ファイルをグループ化する。
- [存在しない] - メタデータキーが存在しない場合、ファイルをグループ化する。
-
[グループ並べ替え順序] - [グループ化]オプションを選択すると、このフィールドがアクティブになり、グループ(グループ内のファイルではなく)を並べ替える順序を指定できます。オプションは次のとおりです。
- [昇順] - 最小値が一番上になるようにグループを並べ替えます。
- [降順] - 最大値が一番上になるようにグループを並べ替えます。
-
[グループ化条件が一致しない場合、ファイルをエラーに送信] - ドキュメントがグループ化ルールに一致しない場合、ファイルをエラーに送信するには、このフィールドのチェックボックスをオンにします。それ以外の場合はボックスを空白のままにします。
グループ化オプションの図については次の図を参照してください。
条件文字列
メタデータでファイルをグループ化する場合、いくつかの条件では検索条件を定義するために関連するフィールドに条件文字列を入力する必要があります。1つ以上のコンマ区切りの値をフィールドに入力でます。検索でファイルのメタデータキー値に複数の一致が見つかった場合、最初に見つかった一致に基づいてファイルがグループ化されます。
たとえば、収集したファイルにメタデータ値「ab、abc、abcd」が含まれているかどうかに基づいてグループ化すると仮定します。次の手順を実行します。
- 検索したい値を含むメタデータキーを選択します。
- 条件として「を含む」を選択します。
- 「ab、abc、abcd」の条件文字列を入力します。
この構成では「abc」や「abcd」のインスタンスが含まれている場合であっても、最初のメタデータ値 (ab) を含むすべてのファイルがグループ化されます。最初のメタデータ値 (ab) を含むすべてのファイルがグループ化されると、ノードは「abcd」のインスタンスが含まれている場合でも、次のメタデータ値(abc)を含むすべてのファイルをグループ化します。この処理はすべてのメタデータ値が検査されるまで継続します。
マージ
このパネルを使用してマージの設定を指定します。次のオプションがあります。
-
[すべてのファイル] - すべてのファイルをマージする。
-
[毎 x ファイル] - 別の出力ファイルに移動する前に、マージされたファイルにマージする単一ファイルの数を指定します。最大100,000個のファイルを1つのマージされたファイルにマージできます。
-
[最大 x バイト] - マージされたファイルにマージされる単一ファイルの最大ファイルサイズを指定します。マージされたファイルの最大ファイルサイズは4GBです。このオプションはマージされたファイルサイズを見積もるために変換された出力形式の一時ファイルを作成するため、パフォーマンスが低下する可能性があることに注意してください。
-
[最大 x ページ] - 単一のファイルからより大きなファイルにマージするページ数を指定します。最大100,000ページを1つのマージされたファイルにマージできます。
-
[各ファイルをマージできることを確認] - マージを試みる前にドキュメントをマージできることを確認するには、このフィールドのチェックボックスをオンにします。このオプションを選択すると、マージできないファイル(たとえば、暗号化されたPDFファイル)は、マージファイルのカウントプロセスによって無視されます。常に各ドキュメントのマージを試みるにはボックスを空白のままにします。このオプションを選択した場合でも、マージできないファイルはマージプロセスによってカウントされます。
たとえば、2つのファイルごとにマージするように設定されているとします。チェックボックスをオンにして2番目のファイルをマージできない場合、2番目のファイルはスキップされ、3番目のファイルは最初のファイルとマージされます。ボックスを空白のままにすると、2番目のファイルはマージできなくてもカウントされ、3番目のファイルは次のシーケンシャルマージファイルに追加されます。
メタデータマージオプションタブ
このタブを使用して、収集されたファイルからメタデータをマージするための設定を指定します。
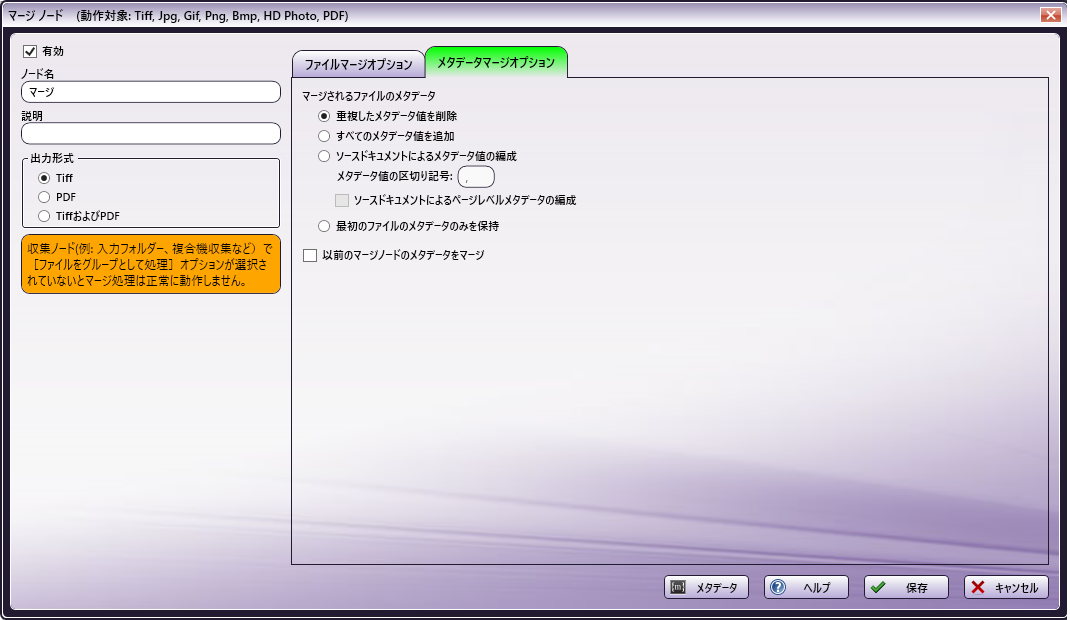
次のフィールドを使用して、マージ時に既存のメタデータを処理する方法を構成します。
- [重複したメタデータ値を削除] - 同じ値を持つドキュメントレベルのメタデータキーをすべて削除します。たとえば、特定のメタデータキーに関連付けられた一意の値のみに関心がある場合はこれを選択します。
例については ここ をクリックしてください。
-
[すべてのメタデータ値を追加] - ドキュメント間で一致するすべてのメタデータキーをマージしてすべての値を保持します。例については ここ をクリックしてください。
-
[ソースドキュメントによるメタデータ値の編成] - ユーザー指定の区切り記号で区切られた、各ドキュメントの複数の値を含むメタデータキーを結合します。 既定 の区切り文字はコンマです。ファイルは merge:input.fullname メタデータキーに従って、マージされたのと同じ順序で一覧表示されます。たとえば、ワークフローでメタデータ値のソースをマージされたドキュメントの値に関連付ける必要がある場合は、このオプションを選択します。例については ここ をクリックしてください。
- [ソースドキュメントによるページレベルメタデータの編成] - merge:input メタデータリストからのインデックスを保持しながら、ドキュメントレベルのメタデータと同じ方法でページレベルのメタデータにインデックスを付けます。このオプションを選択しない場合、ページレベルのメタデータはそのまま結果のドキュメントにマージされます。 ページレベルのメタデータはドキュメントレベルのメタデータとは異なり、マージされたドキュメントと競合しません。
-
[最初のファイルのメタデータのみを保持] - マージされたファイルのメタデータを最初のファイルからコピーして、他のすべてのファイルからメタデータを破棄します。この設定はマージノードのメタデータだけでなく、前のノードのメタデータも無視します。例については ここ をクリックしてください。
-
[以前のマージノードのメタデータをマージ] - ワークフローで複数のマージノードが発生する場合は、このオプションを選択して次のデータを引き継いで更新します。
- merge:input.fullname – 前のマージ操作からの完全なファイル名(名前と拡張子)が保持され、このマージ操作のファイル名はマージされた順序で追加されます。
- merge:input.name – 前のマージ操作からのファイル名(拡張子は含まれない)は保持され、このマージ操作のファイル名はマージされた順序で追加されます。
- merge:input.ext – 前のマージ操作のファイル拡張子は保持され、このマージ操作のファイル拡張子はマージされた順序で追加されます。
- merge:input.size – 前のマージ操作のファイルサイズは保持され、このマージ操作のファイルサイズはマージされた順序で追加されます。
- merge:total – マージされたファイルの総数は、新しくマージされたファイルの数に追加された以前のマージされたファイルの数で更新されます。
注: このオプションを選択せずにワークフローで複数のマージノードが発生した場合、前のマージノードから生成されたメタデータ(たとえば、merge: で始まるすべてのメタデータ)は削除され、引き継がれません。
マージノードメタデータ
次のメタデータはマージノードによって作成されます。
| メタデータ | 説明 |
|---|---|
| merge:input.fullname: | 出力ドキュメントを作成するためにマージされたファイルの名前と拡張子。ファイル名はマージされた順序で表示されます。このメタデータキーは [ソースドキュメントによるメタデータ値の編成] オプションが選択されている場合に、メタデータ情報の出所を特定するために使用できます。 |
| merge:input.name: | 出力ドキュメントを作成するためにマージされたファイルの名前(ファイル拡張子を除く)。ファイル名はマージされた順序で表示されます。このメタデータキーは [ソースドキュメントによるメタデータ値の編成] オプションが選択されている場合に、メタデータ情報の出所を特定するために使用できます。 |
| merge:input.ext: | 出力ドキュメントを作成するためにマージされたファイルのファイル拡張子。merge:input.fullname およびmerge:input.name メタデータを使用して、拡張機能が関連付けられている元のドキュメントを判別できます。 |
| merge:input.size: | 出力ドキュメントを作成するためにマージされたファイルのファイルサイズ。merge:input.fullname およびmerge:input.name メタデータを使用して、サイズが関連付けられている元のドキュメントを判別できます。 |
| merge:input.from: | マージされた各ファイルの最初のページのマージされたドキュメントのページ番号。merge:input.fullname およびmerge:input.name メタデータを使用して、ページ番号が関連付けられている元のドキュメントを判別できます。 |
| merge:input.to: | マージされた各ファイルの最後のページのマージされたドキュメントのページ番号。ページ番号は包括的です。merge:input.fullname およびmerge:input.name メタデータを使用して、ページ番号が関連付けられている元のドキュメントを判別できます。 |
| merge:total.pages: | マージされたページの総数。 |
| merge:total.files: | マージされたファイルの総数。 |
| merge:id: | マージ操作の一意の識別子。 |
マージノードのメタデータの例
このセクションの例は次のサンプルワークフローに基づいています。
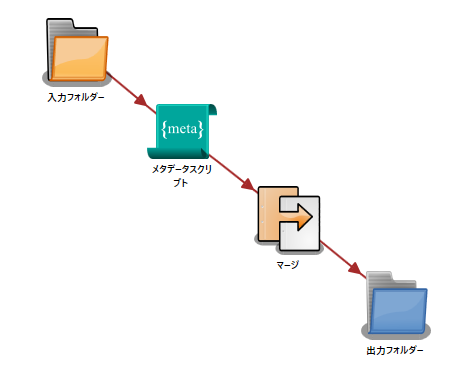
このワークフローでは、
- 入力フォルダー は、2つ以上の画像を収集します。
- メタデータスクリプト ノードは以下を追加します。
- {t:doc} メタデータキーを使用した各画像への単一のドキュメントレベルのメタデータ値。
- {t:page} メタデータキーを使用した各画像の各ページへのページレベルのメタデータ。
3. マージノードはこれら2つのドキュメントとそれらのメタデータをマージします。
- 出力フォルダー は、新しくマージされたドキュメントをフォルダーに配信します。
重複するメタデータ値の削除の例
このセクションでは 重複したメタデータ値を削除 フィールドの効果の例を示します。このオプションを選択すると、ドキュメントがマージされるときに、既定でドキュメントレベルとページレベルのメタデータがマージされ、メタデータキーの冗長な値は削除されます。
例 1:
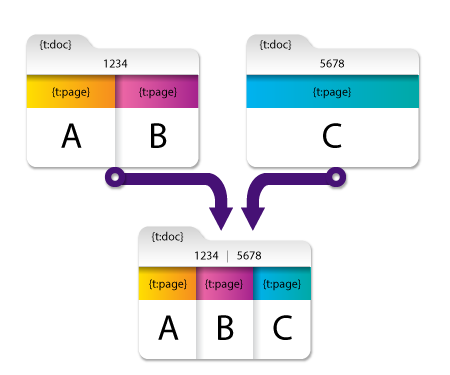
この例では、最初のドキュメントに次のメタデータが含まれています。
- ドキュメントレベルのメタデータ: 値が「1234」である {t:doc}
- ページレベルのメタデータ:
- 最初のページ: 値が「A」である {t:page}
- 2ページ目: 値が「B」である {t:page}
2番目のドキュメントには、次のメタデータが含まれています。
- ドキュメントレベルのメタデータ: 値が「5678」である {t:doc}
- そのページ(のみ)のページレベルのメタデータ: 値が「C」である {t:page}
これらのドキュメントには両方とも同じメタデータキー({t:doc})が含まれていますが、それらの値は一意であり、結果のマージされたドキュメントに引き継がれます。({t:doc})には「1234」と「5678」の2つの値が含まれるようになりました)。それらのページレベルのメタデータもマージされます。
例 2:
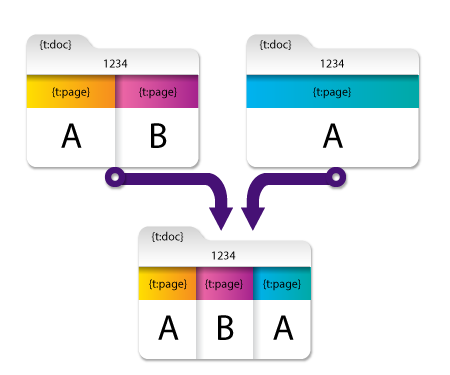
この例では、最初と2番目のドキュメントには同じ値(‘1234’)のドキュメントレベルのメタデータキー({t:doc})があります。 重複したメタデータ値を削除 オプションを有効にすると、{t:doc} の冗長な値がマージされたドキュメントから削除され、単一の値「1234」になります。
注: ページレベルのメタデータ{t:page}は、最初のドキュメントの最初のページと2番目のドキュメントの最初のページが同じメタデータキーと値(「A」)を持っていても削除されないことに注意してください。これは値が異なるページにあるため、冗長とは見なされないためです。
すべてのメタデータ値を追加する例
このセクションでは、 すべてのメタデータ値を追加 フィールドの効果の例を示します。特定のメタデータキーに関連付けられているすべての値に関心がある場合(たとえば、特定のメタデータ値の出現回数をカウントする場合)、このオプションを選択します。
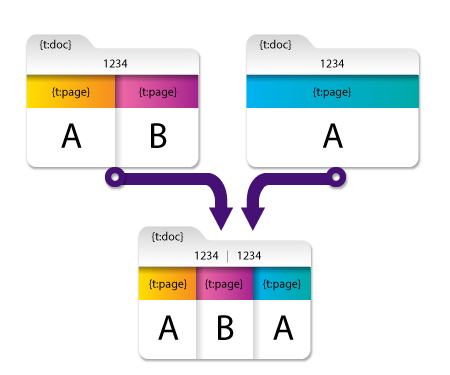
この例では、{t:doc}メタデータキーの両方の値が保持され、結果のマージされたドキュメントには、{t:doc}の2つの値「1234」と「1234」が含まれます。
ソースドキュメントでメタデータ値を整理する例
このセクションでは、 ソースドキュメントによるメタデータ値の編成 フィールドの効果の例を示します。このオプションは、次の図のように、他のオプションとは異なる方法でメタデータを処理します。
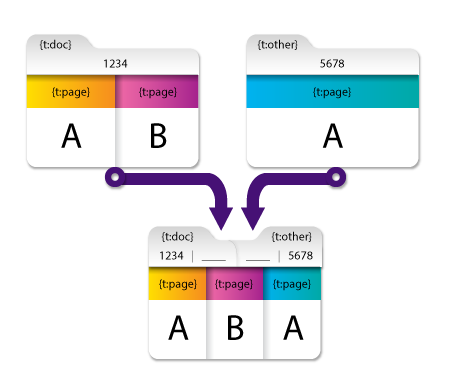
上記の例では、ドキュメントレベルのメタデータに空白が埋め込まれています。これはDispatcher Phoenixのドキュメントレベルのメタデータが次の形式を使用してアクセスされるためです。
\ : \ (例: {t:doc})
これは次の形式の略です。
\ : \ [0] [値 インデックス]
この形式は、たとえば上の図のように、ページレベルのメタデータにも使用されます。
- マージされたドキュメントのページ1の場合、{t:page [1] [1]}を使用して「A」にアクセスできます。
- マージされたドキュメントのページ2の場合、{t:page [2] [1]}を使用して「B」にアクセスできます。
- マージされたドキュメントのページ3の場合、{t:page [3] [1]}を使用して「A」にアクセスできます。
上記の例の結果のマージされたドキュメントでは、
- {t:doc [0] [1]}には最初のドキュメントの値が含まれ、2番目のドキュメントにはそのキーが含まれていなかったため、{t:doc[0] [2]}には空白が含まれています。
- {t:other[0] [1]}は、最初のドキュメントにこのキーの値が含まれていなかったため空白ですが、{t:other [0] [2]}には2番目のドキュメントの値が含まれています。
これにより、値のインデックスをドキュメント名のインデックスと相互参照することで特定のメタデータ値の出所を特定できます。
ソースドキュメントによるページレベルメタデータの編成 オプションを選択すると、結果は次のようになります。
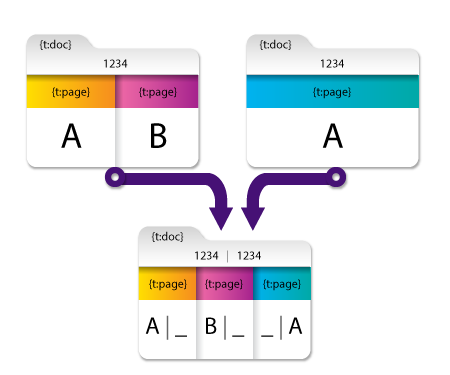
これで結果のマージされたドキュメントには、メタデータの元となったドキュメントを示すページレベルのメタデータブランクが含まれます。
- {t:page[1] [1]} および {t:page [2] [1]} には、最初のドキュメントに由来するため、値「A」および「B」が含まれています。
- {t:page[3] [2]} には、2番目のドキュメントに由来するため、値「A」が含まれています。
これらのオプションを使用すると、ドキュメントレベルおよびページレベルのメタデータをそのソースにマッピングすることができます。
最初のファイルのメタデータのみを保持する例
この例は、 最初のファイルのメタデータのみを保持 フィールドの効果を示しています。
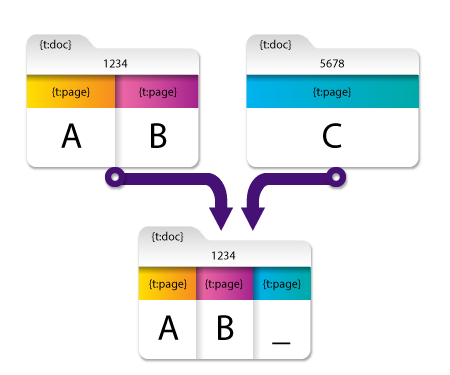
この例では、マージされる2つのファイルにはそれぞれ独自のメタデータがあります。
- ドキュメントレベル(図では「1234」と「5678」の番号で示されています)
- ページレベル(図の A、B、および C)
最初のファイルのメタデータのみを保持 フィールドを選択すると、2つのファイルがマージされますが、最初のファイルのメタデータ(「1234」 と A、B)のみが保持され、2番目のファイルのメタデータ(「5678」と C)は削除されます。
メタデータの集約
1つのドキュメント内の1つのキーに複数のメタデータ値がある場合、値は1つのインデックスに結合され、分割されます(ノード構成中に定義されたユーザー指定の区切り文字による)。例については、次の図を参照してください。
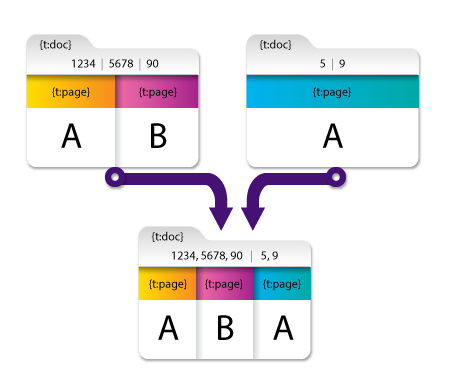
最初のドキュメントでは、{t:doc}に3つの値が含まれ、2番目のドキュメントでは、{t:doc}に2つの値が含まれています。マージされた結果のドキュメントでは、{t:doc[0] [1]} メタデータキーに値「1234、5678、90」が含まれ、{t:doc[0] [2]}に値「5、9」が含まれます。