PDFからデータを抽出

PDFからデータを抽出の処理は、入力PDFファイルからメタデータを抽出するオプションノードです。抽出したメタデータはワークフローの他のノードで後から使用できます(つまり、特定のドキュメントプロパティなどを基に経路を指定できます)。また、検索の目的で他のシステムにインポートできます。この処理では、ユーザーが抽出するメタデータを指定する必要があります。PDFとして開けないファイルの場合、このノードは「エラー」遷移となります。
重要! PDFからデータを抽出ノードから抽出したメタデータは、大文字と小文字が区別されます。ワークフローでメタデータを使用するときは、大文字と小文字を適切に書き分けてください。
サンプルユースケース: PDFのフォームをバッチ処理する場合、フォーム内のフィールドのデータを抽出してデータベースに挿入する必要があります。ワークフローで、入力フォルダーからファイルを収集し、PDFからデータを抽出とODBC処理ノードで処理して、出力フォルダーに処理結果を出力することにより、この処理を自動化できます。
注: このノードは、AES(Advanced Encryption Standard)PDFをサポートしていません。
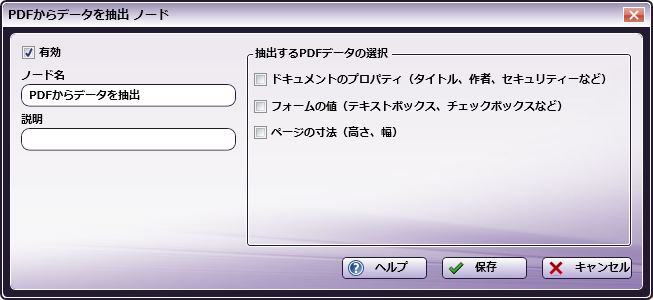
PDFからデータを抽出のウィンドウを開くには、PDFからデータを抽出の処理ノードを追加して、このノードをダブルクリックします。
-
ワークフローに複数の処理がある場合は、 [有効] ボックスをチェックします。チェックしなかった場合、この処理は無視されます。ドキュメントは、あたかもノードが存在しないかのように通過します。無効になっているノードは、論理条件やエラー条件をチェックしないことに注意してください。
-
[ノード名] フィールドに、PDFからデータを抽出ノードのわかりやすい名前を入力します。
-
[説明] フィールドに、PDFからデータを抽出ノードの説明を入力します。これは必須ではありませんが、複数の処理を互いに区別するのに役立ちます。説明が長い場合、このフィールドにマウスを合わせるとその内容全体を読むことができます。
-
[抽出するPDFデータの選択] 領域では、入力ドキュメントから抽出するPDFメタデータを選択できます。
注: ワークフローの他のノードで使用する場合に、[メタデータブラウザー]ウィンドウに表示されるのは、ドキュメントプロパティとページ寸法のメタデータだけです。
以下のオプションを選択して抽出できます。
-
[ドキュメントのプロパティ] - PDFに関する情報です。著者、作成者、題名、タイトル、キーワード、バージョン、ページなどがあります。さらに、暗号化、編集可能、印刷可能の有無や、高解像度印刷に対応するかどうかを表すセキュリティオプションがあります。
-
[フォームの値] - フォームのフィールドの値です。テキストボックス、チェックボックス、ラジオボタンなどが対象となります。PDFのボタンの値は抽出されません。PDFのボタンに関連付けられるのはアクションやラベルだけで、値ではないためです。
-
-
ページの寸法 – ドキュメントの高さと幅。
- PDFからデータを抽出の定義を保存するには、 [保存] ボタンを選択します。 [ヘルプ] ボタンを選択してオンラインヘルプにアクセスすることもできます。また、 [キャンセル] ボタンを選択して、変更を保存しないでウィンドウを終了することもできます。
重要! PDFからデータを抽出 ノードからのメタデータは、本質的に保存されません。ユーザーは、抽出されたデータを取得するために、 メタデータ/ファイル などの追加ノードをワークフローに追加する必要があります。