aiDocuDroid
重要! 2024年10月3日の9.7リリース以降、aiDocuDroidはDispatcher Phoenixで使用できなくなります。この日付以降、新規インストール、アップグレードインストール、または移行インストールには、aiDocuDroid機能は含まれません。aiDocuDroidを含むワークフローは、TesseractまたはOmniPage OCRエンジンを使用するように再構成する必要があります。
aiDocuDroidは、PDFおよびスキャンされたフォームのデジタル画像用のフォーム自動化およびデジタル化ソフトウェアであり、AIベースのICR/OCR、画像処理、およびドキュメントレイアウト分析テクノロジーを備えています。aiDocuDroidは、同一のワークフロー内で印刷、または手書きのテキストでコンテンツが入力されたさまざまなフォーム構造で機能します。次のセクションでは、高度なOCRノードでのaiDocuDroidの使用方法について説明します。
高度なOCRノード
aiDocuDroidを使用して、光学式文字認識(OCR)とインテリジェント文字認識(ICR)の結果を改善し、ゾーンを使用してメタデータを抽出します。ゾーンを介して、 aiDocuDroidエンジン がページ上のテキストを認識する方法を定義することができます。たとえば、受信ドキュメントから請求書番号を取得するために、請求書番号が表示されるドキュメントの領域にゾーンを作成することができます。さらに、ゾーンはメタデータを自動的に抽出し、メタデータを元のドキュメントに関連付けすることができます。
高度なOCRノードのaiDocuDroidは、次のファイルタイプで動作します。
- TIFF
- JPG
- PNG
- BMP
フォーム処理ノード
光学式文字認識(OCR)、およびインテリジェント文字認識(ICR)の結果にaiDocuDroidを使用して、テキスト検索を介して画像化されたドキュメント内の一意の識別子の高度な検索を実行します。情報の正確な内容やページ上の正確な位置を知らなくても、定義したルールに基づいて情報を抽出、または処理(墨消し、強調または取り消し線)することができます。
フォーム処理ノードのaiDocuDroidは、次のファイルタイプで動作します。
- TIFF
- JPG
注:
-
ドキュメントの画像は、カメラではなくスキャナーでキャプチャする必要があります。
-
スキャンされたドキュメントの推奨最小DPIは150dpi以上です。
-
ドキュメントは、10ptより大きく18ptより小さいフォントサイズで印刷する必要があります。
-
抽出する必要のあるフォームに関する情報は、ノイズやその他のアーティファクトによって損傷しないようにする必要があります。
-
CPUバージョンは動作可能ですが、非常に低速です。パフォーマンスを向上させるためにGPUをお勧めします。NVIDIA Geforce GTX 1650(4GB、10.2 CUDAサポート)または、より強力で高速なGPUカードをお勧めします。
-
aiDocuDroidエンジンは、64ビットオペレーティングシステムでのみ動作し、32ビットオペレーティングシステムではサポートされていません。
AIDocuDroidエンジン
aiDocuDroidは、 高度なOCR および フォーム処理 ノードで次のOCR/ICRエンジンをサポートしています。
- aiDocuDroid (OCR)
- aiDocuDroid手書き(ICR)
プロパティウィンドウ - 高度なOCRノード
高度なOCRノードでaiDocuDroidを構成するには、ノードをワークフロービルダーの作業領域にドラッグアンドドロップしてダブルクリックします。次の図のように、高度なOCRノードのプロパティウィンドウが表示されます。

上の図は、プロパティウィンドウの既定の構成を示しています。次の図のように、ドロップダウンからaiDocuDroidとaiDocuDroid手書きとの間でOCRエンジンを変更することができます。

プロパティウインドウ - フォーム処理ノード
フォーム処理ノードでaiDocuDroidを構成するには、ノードをワークフロービルダーの作業領域にドラッグアンドドロップし、ダブルクリックします。次の図のように、フォーム処理ノードのプロパティウィンドウが表示されます。

上の図はプロパティウィンドウの既定の構成を示しています。次の図のように、ドロップダウンからaiDocuDroidとaiDocuDroid手書きの間でOCRエンジンを変更できます。
注: ワークフローを実行する前に、サンプルイメージをフォーム処理ノードにアップロードする必要があります。サンプルドキュメントがノードに関連付けられていない場合、正しいテキストが存在するにもかかわらず、フォーム用に作成されたルールがトリガーされない可能性があります。
一般設定 - 高度なOCRノード
ゾーンのタイプ/コンテンツの定義
ゾーンコンテンツの特定の形式に一致するように、各ゾーンの設定を選択できます。プレビュー領域でゾーンを選択した状態で、ツールバーの![]() アイコンをクリックして、ゾーンタイプドロップダウンパレットを表示します。次に、ゾーンのタイプを選択します。現在、aiDocuDroidエンジン はテキストゾーンタイプのみをサポートしています。
アイコンをクリックして、ゾーンタイプドロップダウンパレットを表示します。次に、ゾーンのタイプを選択します。現在、aiDocuDroidエンジン はテキストゾーンタイプのみをサポートしています。
出力フォーマットの選択
[出力]フィールドを使用して、出力ファイルの形式を指定します。この領域は、ページの左側、ゾーンリストの下に表示されます。
[出力]フィールドでドロップダウンをクリックすると、出力オプションのリストが表示されます。 aiDocuDroidエンジン は、このフィールドで使用可能なオプションのリストに影響を与える可能性があります。オプションが[出力]フィールドに表示されない場合、オプションはそのエンジンでサポートされていません。以下の表を参照してください。
注: 処理されたすべての出力ファイルには、次の例外を除いて、ユーザー定義ゾーンでキャプチャされたコンテンツのみが含まれます。これらの出力形式には、ゾーンでキャプチャされたコンテンツとともに元のファイルが含まれます。
- 元のドキュメント + メタデータ
| 出力オプション | aiDocuDroid | aiDocuDroid手書き |
|---|---|---|
| 元のドキュメント + メタデータ - 定義されたゾーンから抽出されたメタデータとともに元のファイルを出力します。これは既定の設定であり、さらに処理するために、ワークフロー内の他のノード(メタデータ/ファイル、メタデータ経路指定など)でメタデータを使用するために必要です。 | Y | Y |
| テキスト - ほとんどのテキストエディターやワードプロセッサで読み取れるプレーンテキスト (*.TXT) としてドキュメントを出力します。 | Y | Y |
| カンマ区切りテキスト - ドキュメントを、Excel (*.CSV)で読み取ることができるテーブル化されたテキストファイルとして出力します。 | Y | Y |
| フォーマット済みテキスト - ドキュメントを *.TXTファイルとして出力し、追加のスペースを挿入してページのレイアウトを維持します。 | Y | Y |
| テキストと改行 - 各行の後に改行を入れてドキュメントをテキストとして出力します。 | Y | Y |
| Unicodeのテキスト - 2バイトのUnicode文字を使用して、ドキュメントをプレーンテキストとして出力します。 | Y | Y |
| Unicodeのカンマ区切りテキスト - 2バイトのUnicode文字を使用して、ドキュメントをテーブル化されたテキストファイルとして出力します。出力されたファイルはExcelで読み取ることができます。 | Y | Y |
| Unicodeのフォーマット済みテキスト - 2バイトのUnicode文字を使用して、フォーマットされたテキストとしてドキュメントを出力します。 | Y | Y |
| 改行を含むUnicodeのテキスト - 各行の後に改行を入れてドキュメントをテキストとして出力し、2バイトのUnicode文字を使用します。 | Y | Y |
| XML - ドキュメントをXMLファイル形式で出力します。 | Y | Y |
| 検索可能なPDF - 元の画像を前景に保持し、認識されたテキストを背景に (正しい位置に)隠すPDF出力コンバーター。検索可能なPDF出力ファイルの最大ページ数は8191ページです。 | Y | Y |
ゾーンの作成
aiDocuDroidエンジン は、手動ゾーン作成 のみをサポートします。自動ゾーン作成はサポートされていません。
注:
-
テストゾーン機能は、aiDocuDroidエンジンではサポートされていません。aiDocuDroidエンジンでは、プレビューツールバーの 自動ゾーン作成 アイコン (
 ) と テストゾーン アイコン (
) と テストゾーン アイコン ( )、およびゾーンリストの このゾーンのテスト と 選択したゾーンのテスト オプションは表示/有効化されません。
)、およびゾーンリストの このゾーンのテスト と 選択したゾーンのテスト オプションは表示/有効化されません。 -
作成されたゾーンは、さまざまなサイズの入力ドキュメントイメージに対してインテリジェントに調整され、ターゲットのテキストを抽出できるようにします。
詳細設定 - フォーム処理ノード
フォーム処理ノードでaiDocuDroidを使用する場合の一般的な設定は、他のOCRエンジンと同様です。詳細は フォーム処理ノード を参照してください。
aiDocuDroidは、チェックボックスを処理する機能も提供します。このため、一部のメニューの外観と機能が多少異なります。これらの違いについては以下で説明します。
フォーム処理チェックボックスの認識
aiDocuDroidエンジンは、入力ドキュメントでチェックボックスがマークされているかどうかの認識に加えて、フォーム内のさまざまなタイプのチェックボックスの検出をサポートしています。
チェックボックスは、画像内の単純なマーキングに基づいて「true」または「false」として示すことができるフォームの要素で構成されています。標準と非標準の2つの一般的なタイプのチェックボックスがサポートされています。
標準のチェックボックス
標準チェックボックスは、通常、テキストラベルに隣接する小さな正方形、または長方形で構成されます。
[正方形]チェックボックスの例:

[長方形]チェックボックスの例:

非標準のチェックボックス
非標準のチェックボックスには、通常ラベルの横にある円、下線、カッコなどの多くのスタイルが含まれます。これには、ラベル自体が丸で囲まれているか、マークされているチェックボックスも含まれます。
[円形]チェックボックスの例:

[下線]チェックボックスの例:

[カッコ]チェックボックスの例:

チェックボックスとしての[ラベル]の例:

チェックボックスルールの自動検出
フォームは多数のチェックボックスで構成される可能性があるため、チェックボックスルールの作成を容易にする自動検出メカニズムが用意されています。追加のオプションは、 [新しいルールの追加] ダイアログの [ルールタイプ] で使用できます。

- フォーム処理 : このオプションは、一般的なテキスト検索ルールを作成する場合や、チェックボックスルールを手動で作成する場合に使用します(後述)。
- チェックボックス検出 : このオプションを使用して、自動チェックボックスルール作成用の関心領域(ROI)を作成します。
チェックボックス検出 ルールを作成した後、 他のルールと同様に寸法を調整できます。設定できる追加オプションがいくつかあります。

検出されるチェックボックスを構成するには、次の設定を行います。
- 検索タイプ : [標準] チェックボックスと [非標準] チェックボックスのいずれかを検出するための2つの追加オプションがあります。この場合、標準のチェックボックスが検出されます。
- 検索モード と 検索対象 : これらのオプションは、通常のテキスト検索ルールとまったく同じように機能します。これらは、検出されるチェックボックスを制限するために使用されます。検索設定に一致するラベルを持つチェックボックスのみがルールとして作成されます。 [ノーマル] 検索モードの場合、1行に1つずつ複数のチェックボックスラベルを表示できます。原則として、このリストにラベルが付いているチェックボックスは返されます。
- チェックボックスの位置 : このオプションを使用して関連するラベルに対してチェックボックス自体をどのように配置するかを制御します。 [左] はチェックボックスがラベルの前にあることを示し、 [右] はラベルの後にあることを示します。
チェックボックスの自動検出は、空白のテンプレート(まだマークされていないテンプレート)を使用して実行する必要があります。すでにマーキングが付いているチェックボックスの検出は失敗する可能性があります。このような場合は、自動的に検出されないチェックボックスを手動で作成できます。
チェックボックス検出 ルールは基本ルールとしてのみ作成でき、サブルールとして作成することはできません。複数の チェックボックス検出 ルールを作成できます。必要なルールがすべて作成されたら、 [チェックボックス検出を実行] ボタンをクリックして検出を開始できます。

チェックボックス検出が完了すると、 チェックボックス検出 ルールはそれぞれ1つ以上のチェックマークルールに置き換えられます。

自動生成されたルールの名前はチェックボックスで検出されたラベルテキストの前に元の チェックボックス検出 ルール名が付加されます。
非標準のチェックボックスの自動検出も同様です。必要なチェックボックスをすべて含む チェックボックス検出 ルールを作成できますが、 検索タイプ を 非標準のチェックボックス に設定します。

非標準のチェックボックスを検出する場合は、 チェックボックスの位置 とともに1つの追加オプションを使用できます。 [チェックボックスとしてラベル付け] がオンになっている場合、テキスト自体はチェックボックスとして扱われます。これは、オプションがチェックされていることを示すために、ラベルを丸で囲んだり下線で囲んだりする場合に使用します。このオプションを選択すると、 [チェックボックスの位置] チェックボックスは無効になり、グレー表示されます。
非標準のチェックボックスの自動検出結果は、標準チェックボックスの場合と同じように動作します。
チェックボックスルールの手動作成
場合によっては、自動検出なしでチェックボックスルールを作成する必要があります。これは、フォームの固有の特性により、1つ以上のチェックボックスが適切に自動検出されない場合がほとんどです。また、前述のように、 チェックボックス検出 ルールはサブルールとして作成できません。チェックマーク認識をサブルールとして実行する場合は、ルールを手動で作成する必要があります。
チェックボックスルールの作成は、通常のテキスト検索ルールの作成とほぼ同じです。ルールを最初に作成するときは、 [ルールタイプ] を [フォーム処理] に設定する必要があります。

手動で作成されたチェックボックスルールの 検索タイプ は [標準チェックボックス] または [非標準のチェックボックス] のいずれかに設定する必要があります。

ルール境界を作成するときは、チェックマークの認識を容易にするために、寸法がチェックボックス自体の寸法と密接に一致する必要があります。

メタデータ
チェックボックスルールが自動的に検出されると、 [操作] の下の[メタデータ]タブにも自動的に入力されます。メタデータキーは、自動的に生成されたルール名と一致します。

チェックボックスルールを手動で作成した場合、メタデータ構成は自動的に作成されません。必要な メタデータキー を手動で入力する必要があります。

[重複を削除] オプションは、手動で作成したルールがサブルールの場合にのみ使用できます。
チェックボックスルールを使用してフォームを処理する場合、チェックマークが検出されると、メタデータ値は「1」に設定されます。それ以外の場合は「0」に設定されます。
認識
ワークフローが実行されると、チェックボックスルールが入力ファイルに従って処理され、チェックボックスがマークされているかどうかが判断されます。チェックマークの認識は、使用されるマークの種類によって異なります。一般的に、他のページコンテンツと重複しない明確なマーキングは認識のための最良の結果を与えます。
チェックマーク検出は、ワークフローが空白のテンプレート(マークされていないテンプレート)で構成されている場合に最も効果的です。マークされたテンプレートを使用すると、入力ファイルのチェックマーク検出の精度が低下します。
サポートされているチェックマーク
サポートされているチェックマークの例は次の通りです。

ラベル自体がチェックボックスの場合、ラベルが完全に丸で囲まれているときに認識が最適になります。

サポートされていないチェックマーク
チェックマークが正しく検出されない場合がいくつかあります。
この場合、チェックボックスはルールに指定された領域の外側でマークされます。

この場合、上部のチェックボックスは意図したとおりにマークされたものとして表示される可能性がありますが、下部のチェックボックスもマークされたものとして表示される可能性があります。

この例では、マーキングは非常に最小限であるため、マーキング済みとして示される可能性は低いです。

詳細設定 - 高度なOCRノードとフォーム処理ノード
aiDocuDroidエンジン は、詳細設定を使用して、OCR/ICR結果の精度とOCR/ICR処理のパフォーマンス時間を調整します。高度なOCRノードには、OCR/ICR設定ウィンドウにアクセスする[詳細設定]ボタンが含まれています。
[詳細設定]ウィンドウにアクセスすると、使用可能なオプションのセットは、エンジンの機能に基づいてaiDocuDroidエンジンによって決定されます。
[詳細設定]ウィンドウには、次のタブがあり、それぞれに関連する設定のセットがあります。次の設定を指定できます。
注: aiDocuDroidエンジンは、出力ドキュメント作成の 出力 形式設定をサポートしていません。
前処理タブ
このタブを使用して、OCR/ICR分析および認識を開始する前にイメージを準備、および、前処理する方法を指定するパラメーターを設定します。以下の図は、 aiDocuDroidエンジン で使用可能なオプションを示しています。すべてのオプションは、図の下のセクションで説明されています。
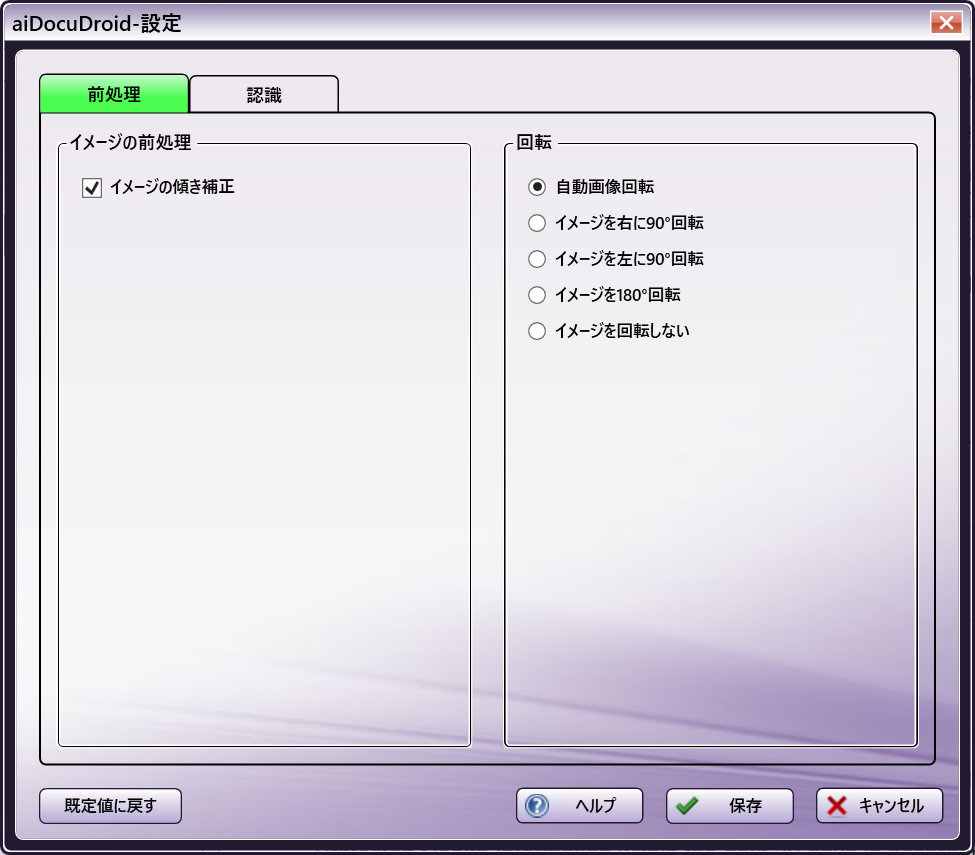
aiDocuDroid オプション
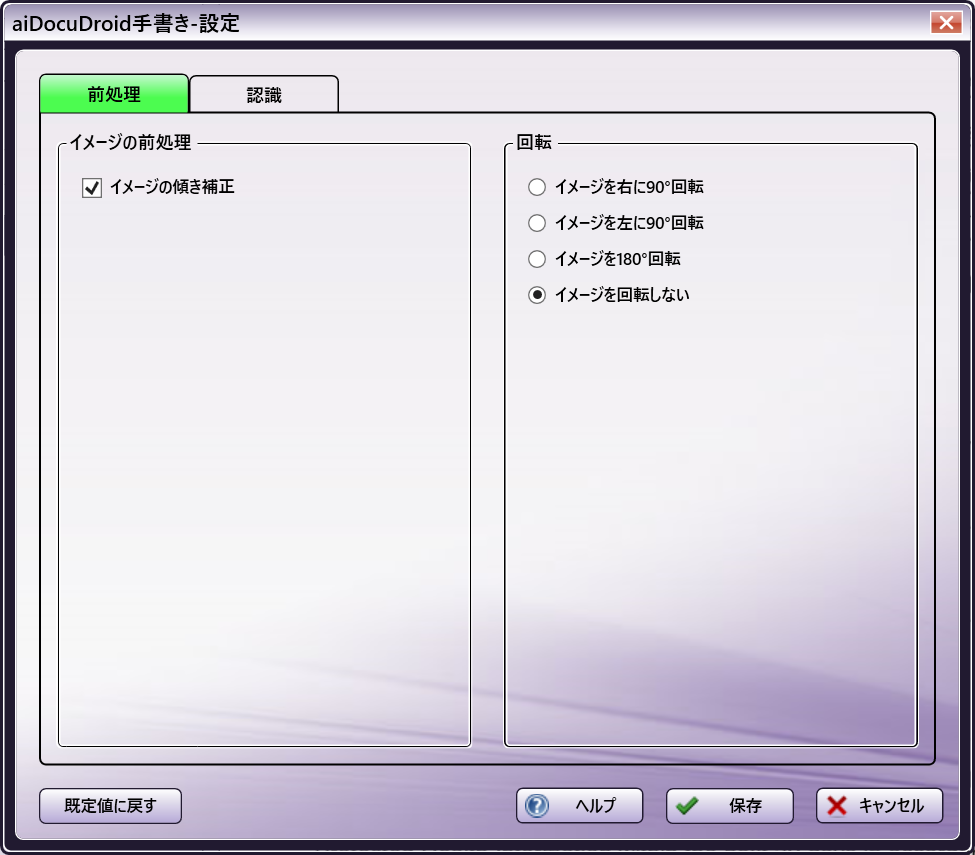
aiDocuDroid手書き オプション
イメージの前処理
OCR/ICR認識を実行する前に、前処理手順をイメージに適用して画像の品質を向上させることができます。これらのオプションを有効、または、無効にすると、出力の品質やOCR/ICR処理のパフォーマンス時間が向上する場合があります。
-
イメージの傾き補正 - この設定を有効にすると、曲がってスキャンされた画像は、準備処理中に自動的にまっすぐになります。既定値は[有効]です。
注: イメージの傾き補正 の前処理オプションをオフにすると、OCR/ICR処理が失敗する可能性があります。このオプションをオフにした場合、ドキュメントを適切に処理できるように、ワークフローにイメージの傾き補正ノードを追加する必要がある場合があります。
回転
OCR/ICRを実行する前に、アプリケーションは誤った方向のページを検出して修正しようとします。受信ファイルの正確なずれを既に認識していて、この自動検出処理を回避することで処理時間を短縮したい場合は、ここで特定のオプションを選択することができます。
-
自動画像回転 - このオプションは、aiDocuDroidエンジンでのみ使用できます。この設定を有効にすると、OCRが実行される前に、受信画像の向きが検出され、不適切な向きのページ画像が自動的に回転します(90、180、または270度)。この有効なオプションは、回転とミラーリングの既定値です。
-
イメージを右に90°回転 - この設定を有効にすると、不適切な向きのページ画像は、時計回りに90度回転します。
-
イメージを左に90°回転 - この設定を有効にすると、不適切な向きのページ画像は、反時計回りに90度回転します。
-
イメージを180°回転 - この設定を有効にすると、不適切な向きのページ画像が上下逆になります。
-
イメージを回転しない - この設定を有効にすると、画像は回転しません。
認識タブ
OCR/ICRの精度と処理時間を改善するために、認識処理をアシストする特定の設定を指定することができます。
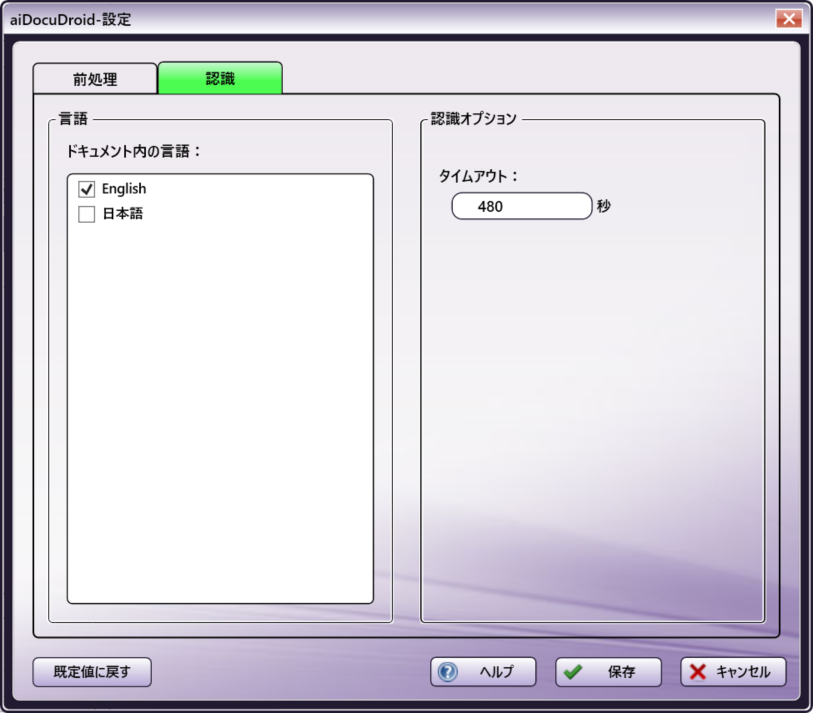
aiDocuDroid オプション
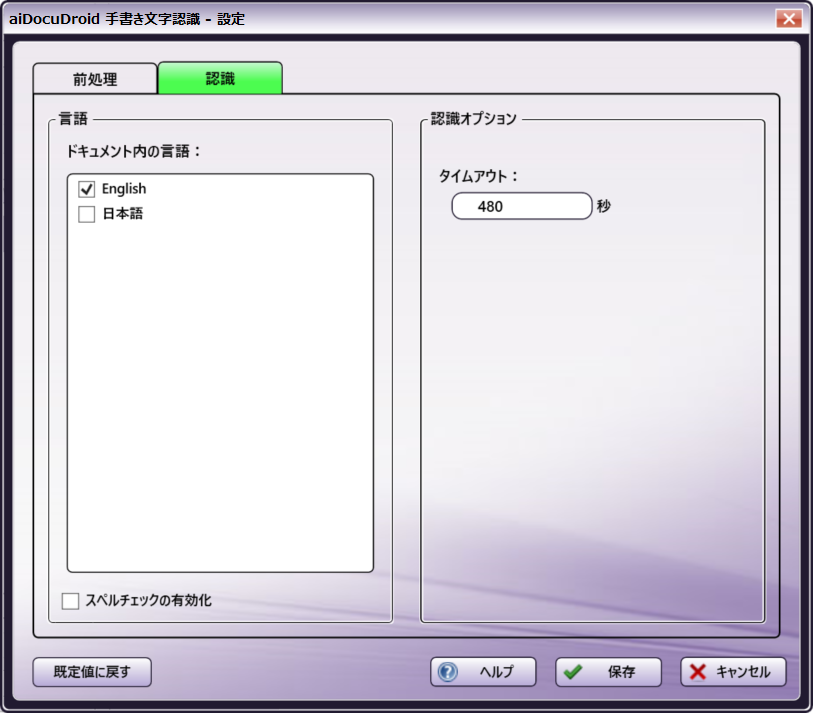
aiDocuDroid手書き オプション
言語
-
ドキュメント内の言語 - このウィンドウには、aiDocuDroidエンジン で現在サポートされているすべての言語が表示されます。OCR/ICR認識処理に含める言語の横にあるボックスをチェックします。少なくとも1つの言語を選択する必要があります。aiDocuDroidエンジンは現在、英語、フランス語、ドイツ語、日本語のOCRをサポートしています。手書き認識では英語と日本語のみがサポートされます。英語と日本語は同時に選択できますが、ただし、他の言語を組み合わせて選択することはできません。既定の言語は英語です。
-
スペルチェックの有効化 - このオプションは、aiDocuDroid手書きOCR English(英語)エンジンでのみ使用できます。OCR認識中にスペルチェックを有効にするには、このチェックボックスをオンにします。
提案ベースのスペルチェッカーとは異なり、aiDocuDroidスペルチェッカーは、監視されていない方法で、認識エンジンの出力からスペルミスのある単語(認識エラー)を自動的に修正します。aiDocuDroidスペルチェッカーは、スペルミスの可能性のある単語と、修正されたスペルペアの数百万を超える例でトレーニングされたディープラーニングモデルです。
-
[言語を追加] - このボタンをクリックすると、新しいウィンドウが表示され、そこからサポートされている追加の言語をインストールできます。使用可能だがインストールされていない言語がすべてこのウィンドウにリストされます。インストールすると、ドキュメント内の言語 ウィンドウで使用できるようになります。

認識オプション
-
タイムアウト - OCR/ICR認識処理がタイムアウトになるまでに経過する時間を秒単位で指定します。既定のタイムアウト期間は480秒です。
-
空白のページを削除 - 入力イメージの空白ページを検出して出力ファイルから除外するかどうかを指定します。これは、検索可能なPDFなど、ページ分割された出力タイプにのみ影響します。
選択すると、[コンテンツ感度]スライダーを使用して、ページ上に存在し、「空白」と見なされる余分なコンテンツの量を制御することができます。スライダーを「クリーン」側に設定すると、白紙と見なされるページが少なくなり、「ノイズ」側に設定すると、白紙と見なされたまま、ページ上のマーキングの度合いが高くなります。
フォーム処理の追加オプション
フォーム処理ノードからこのメニューにアクセスすると、[空白のページを削除]の代わりに別のオプションが使用可能になります。

-
検索許容値 - 「あいまい検索」を選択した場合の厳密な一致を設定できます。許容値を高く設定することで、OCRの結果にエラーがあった場合でも検索結果を一致させることができます。これを低い許容値に設定すると、類似した単語による誤った一致を防ぐことができます。特に、小さな単語(4文字または5文字未満)を検索する場合、あいまい検索は多数の誤った結果を示す可能性があるため、許容範囲を低く設定するか、あいまい検索を完全に無効にすることが最適な場合があります。
手書きテキストの認識は、特にエラーが発生しやすい可能性があります。したがって、手書きテキストにはあいまい検索を使用し、より高い許容値を使用することを検討することを強くお勧めします。