OCRとバーコードの設定
このトピックでは、OCR設定ウィンドウについて説明します。このウィンドウは、光学式文字認識(OCR)をサポートするDispatcher Phoenixノードで使用できます。これらのノードには、OCR設定ウィンドウにアクセスする [詳細設定] ボタン( 高度なOCR設定 ボタンと呼ばれることもあります)が含まれています。次の図を参照してください。
注: このページは主にTesseractとOmniPageに適用されます。ZXingバーコードエンジンの設定については 以下 で説明します。
OCRエンジン
光学式文字認識は、OCRエンジンによって駆動されます。Dispatcher Phoenixは現在、次のOCRエンジンをサポートしています。
- Tesseract
- OmniPage
各OCR対応ノードは、1つ以上のOCRエンジンをサポートします。ノードが1つのOCRエンジンのみをサポートする場合、そのエンジンは既定になります。既定がTesseractであるノードの場合、ノードのプロパティウィンドウの「OCRエンジン」フィールドに「Tesseract」と表示されます。ただし、Tesseractをサポートしないノードの場合、OmniPageが既定になりますが、OCRエンジンフィールドには「OmniPage」が表示されません。
ノードが複数のエンジンをサポートしており、さらに複数のエンジンのライセンスを取得している場合、ノードの OCRエンジン フィールドにドロップダウンメニューが表示され、エンジンを選択することができます。
OCR設定ウィンドウにアクセスすると、使用可能なオプションのセットはエンジンの特徴/機能に基づいてOCRエンジンによって決定されます。
注: OCR対応ノードの場合、OCRエンジンは、ノードのプロパティウィンドウの 出力 フィールドで使用できる出力オプションのリストにも影響を与える可能性があります。
OCR対応ノード
次のDispatcher Phoenix処理ノードには、OCR機能が搭載されています。
OmniPage ノード
すべてのOCR対応ノードは、OmniPage OCRエンジンをサポートしています。これらのノードは、以下の例外を除いたDispatcher Phoenix基本ライセンス用のアドインノード、または、Dispatcher Phoenixバーティカル市場パッケージの一部として購入する必要があります。
- 高度なOCR - 高度なOCRは、DispatcherPhoenix 基本ライセンスに含まれています。TesseractとOmniPageのサポートが含まれています。高度なOCR用OmniPageは個別に購入できます。
- PDFに変換 - PDFに変換は、Dispatcher Phoenix基本ライセンスに含まれています。Tesseractのサポートが含まれています。PDFに変換用OmniPageは個別に購入できます。
重要! OmniPage OCRエンジンを使用して英語以外の言語をスキャンする場合、スキャンされた文字列に3文字以上が含まれ、各文字が30x30から48x48ピクセルの場合に最適な結果が返されます。
すべてのバーコード対応ノードは、OmniPageバーコードエンジンをサポートします。
- 2Dバーコード処理 - 2Dバーコード処理は、ZXingバーコードエンジンを備えたDispatcher Phoenix基本ライセンスに含まれています。OmniPageによる2Dバーコード処理はアドインノードとして利用することができます。
- バーコード処理 - バーコード処理は、ZXingバーコード エンジンを備えたDispatcher Phoenix基本ライセンスに含まれています。OmniPageによるバーコード処理はアドインノードとして利用することができます。
Tesseractノード
次のノードはTesseract OCRエンジンをサポートしています。
- 高度なOCR - 高度なOCRは、DispatcherPhoenix基本ライセンスに含まれています。Tesseractのサポートが含まれています。
- PDFに変換 - PDFに変換は、Dispatcher Phoenix基本ライセンスに含まれています。Tesseractのサポートが含まれています。
- フォーム処理 - フォーム処理ノードを購入すると、TesseractとOmniPage OCRエンジン両方のサポートが含まれています。
注: Tesseract OCRエンジンには、OCR認識処理で使用する追加の言語をインストールするオプションが含まれています。これらの追加言語はTesseract OCRエンジンに含まれており、追加のライセンスや購入は必要ありません。
複数のOCRエンジンノード
このセクションにはOmniPageとTesseractの両方のOCRエンジンをサポートする各Dispatcher Phoenixノードの表が含まれています。この表は、各OCRエンジンでサポートされているDispatcher Phoenixの機能と機能を示しています。
高度なOCRノード - OCR機能表
| OCR 特徴/機能 | OmniPage | Tesseract |
|---|---|---|
| 自動ゾーン | Yes | Yes |
| 処理するページ範囲 | すべてのページ すべての偶数ページ すべての奇数ページ 最初のページ 最後のページ 独自のページ範囲を定義 |
すべてのページ すべての偶数ページ すべての奇数ページ 最初のページ 最後のページ 独自のページ範囲を定義 |
| 出力 | 元のドキュメント+メタデータ 検索可能なPDF イメージ置き換え付きのPDF Microsoft Word 2000 XP (*.doc) Microsoft Word 2003 (WordML) Microsoft Word 2003 XP (*.xls) Microsoft Powerpoint 97 (*.ppt) 検索可能なXPS RTF Word 2000 テキスト カンマ区切りテキスト フォーマット済みテキスト テキストと改行 Unicodeのテキスト Unicodeのカンマ区切りテキスト Unicodeのフォーマット済みテキスト 改行を含むUnicodeのテキスト XML eBook |
元のドキュメント+メタデータ 検索可能なPDF テキスト カンマ区切りテキスト テキストと改行 Unicodeのテキスト Unicodeのカンマ区切りテキスト 改行を含むUnicodeのテキスト |
| 高度な設定 | Yes | Yes |
| 前処理 | ノイズ除去 傾き補正 ファクス補正 ネガポジ反転 イメージ解像度の向上 回転 |
傾き補正 回転 |
| 認識 | 127 言語 9 辞書 スペルチェック レイアウトの説明: - 自動 - 1列、表なし - 複数列、表なし - 1列、表あり - スプレッドシート - フォーム - 法律的訴答 OCR処理の最適化 イメージの最大サイズを指定 タイムアウト |
113 言語 レイアウトの説明: - 自動 - 1列、表なし - 複数列、表なし - 1列、表あり - スプレッドシート OCR処理の最適化 最大画像サイズを指定 タイムアウト |
| OCR設定の出力 | 出力フォーマットのレベル 入力されたフォームデータを保持する 反転したテキストを保持する テキストと背景色を保持 空白ページの削除 認識されない文字の代替文字 |
なし |
PDFに変換 - OCR機能表
| OCR 特徴/機能 | OmniPage | Tesseract |
|---|---|---|
| ファイルタイプ | PDF 編集済みPDF PDFイメージのみ 検索可能なPDF イメージ置き換え付きのPDF |
検索可能なPDF PDFイメージのみ |
| PDFバージョン | 品質の最適化 サイズの最適化 PDF 1.3 PDF 1.4 PDF 1.5 PDF 1.6 PDF 1.7 PDF/A-1a PDF/A-2a PDF/A-3a PDF/A-1b PDF/A-2b PDF/A-3b PDF/A-2u PDF/A-3u |
なし |
| 空白のページを削除 | Yes | Yes |
| 自動画像回転 | Yes | Yes |
| セキュリティの設定 | Yes | Yes |
| 詳細設定 | Yes | Yes |
| 前処理 | ノイズ除去 傾き補正 ファクス補正 ネガポジ反転 イメージ解像度の向上 回転 |
傾き補正 回転 |
| 認識 | 127 言語 9 辞書 スペルチェック レイアウトの説明: - 自動 - 1列、表なし - 複数列、表なし - 1列、表あり - スプレッドシート - フォーム - 法律的訴答 OCR処理の最適化 イメージの最大サイズを指定 タイムアウト |
113 言語 レイアウトの説明: - 自動 - 1列、表なし - 複数列、表なし - 1列、表あり - スプレッドシート OCR処理の最適化 イメージの最大サイズを指定 タイムアウト |
| OCR設定出力 | 出力フォーマットのレベル 塗りつぶしフォームデータを保持 反転したテキストを保持 テキストと背景色を保持 空白ページの削除 認識されない文字の代替文字 |
空白ページの削除 |
フォーム処理 - OCR機能表
| OCR 特徴/機能 | OmniPage | Tesseract |
|---|---|---|
| ルール構成の実行 | Yes | Yes |
| 詳細設定 | Yes | Yes |
| 前処理 | ノイズ除去 傾き補正 ファクス補正 ネガポジ反転 イメージ解像度の向上 回転 |
傾き補正 回転 |
| 認識 | 127 言語 9 辞書 スペルチェック レイアウトの説明: - 自動 - 1列、表なし - 複数列、表なし - 1列、表あり - スプレッドシート - フォーム - 法律的訴答 OCR処理の最適化 イメージの最大サイズを指定 タイムアウト |
113 言語 レイアウトの説明: - 自動 - 1列、表なし - 複数列、表なし - 1列、表あり - スプレッドシート OCR処理の最適化 イメージの最大サイズを指定 タイムアウト |
高度なOCR設定ウィンドウの使用
高度なOCR設定ウィンドウには、OCR結果の精度とOCR処理の実行時間を調整するために使用できる設定が含まれています。
高度なOCR設定ウィンドウには、次のタブがあり、それぞれに関連する設定のセットがあります。次の設定を指定できます。
ボタン
次のボタンはOCR設定ウィンドウの各タブから使用することができます。
- [既定値に戻す] - カスタマイズされたすべての設定を既定値にリセットするには、このボタンをクリックします。
- [ヘルプ] - このウィンドウのオンラインヘルプにアクセスするには、このボタンをクリックします。
- [保存] - 現在のOCR設定を保持するには、このボタンをクリックします。
- [キャンセル] - 変更を保存せずにOCR設定ウィンドウを終了し、ノードのプロパティウィンドウに戻るには、このボタンをクリックします。
前処理タブ
このタブを使用して、OCR分析と認識を開始する前に、イメージを準備、および前処理する方法を指定するパラメーターを設定します。
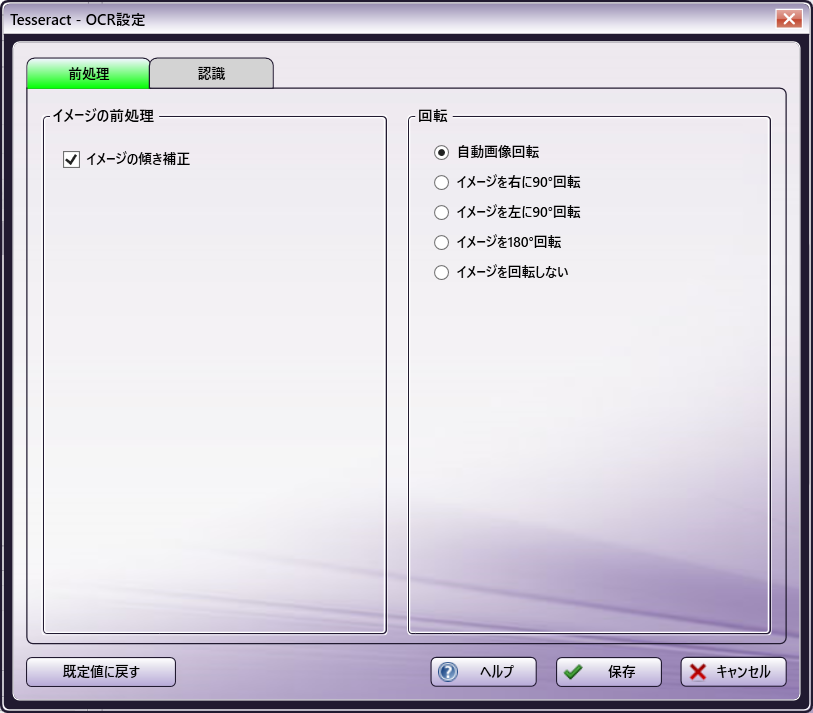
注: このタブで使用できるオプションのセットは、エンジンの特徴/機能に基づいて、 OCRエンジン によって決定されます。オプションがタブに表示されない場合、そのオプションはOCRエンジンでサポートされていません。以下の図は、OmniPageおよびTesseract OCRエンジンで使用可能なオプションを示しています。すべてのオプションは、図の下のセクションで説明されています。
OmniPageオプション
Tesseractオプション
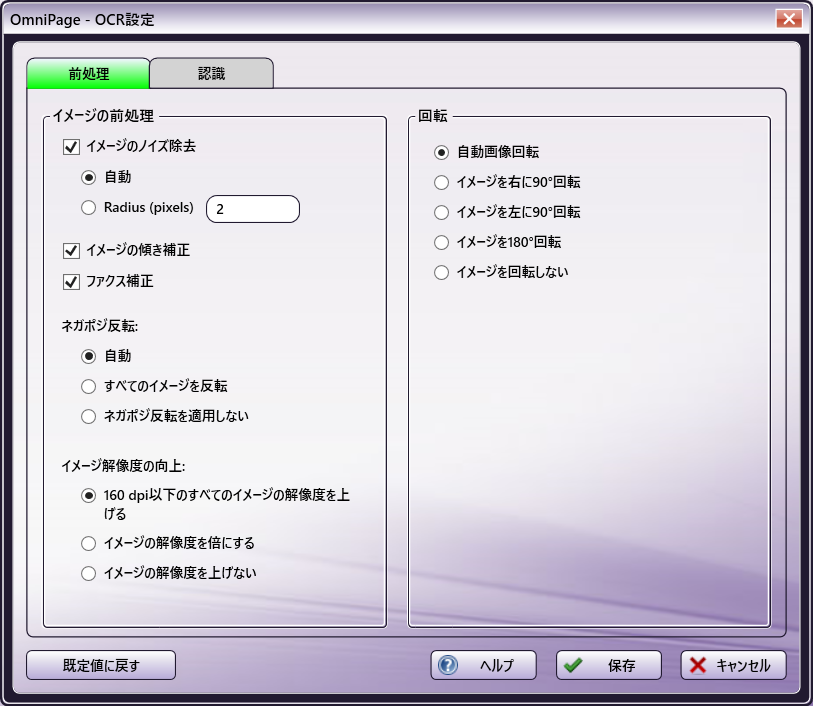
イメージの前処理
OCR認識を実行する前に、イメージに前処理を適用してイメージの品質を向上することができます。これらのオプションを有効、または無効にすると、出力の品質やOCR処理のパフォーマンス時間が向上する場合があります。
-
[イメージのノイズ除去] - この設定を有効にすると、準備処理中にOCR用にイメージのノイズが自動的に除去されます。OCR処理は低品質のイメージを許容しますが、最良の結果を得るにはイメージからノイズや汚れを取り除く必要があります。ノイズ除去は、スキャンされたイメージのノイズを探し、取り除きます。既定値は「有効」です。
-
[自動] - この設定を有効にすると、OCRエンジンは斑点除去のピクセル半径を自動的に選択します。
-
[半径 (ピクセル)] - この設定を有効にすると、ユーザーはOCRエンジンが斑点除去に使用するピクセル半径を設定します。
注: このオプションは、2Dバーコード処理、高度なOCR、バーコード処理、PDFへ変換、およびフォーム処理ノードでのみ使用できます。このオプションは、Officeへ変換、仕分け、強調/取り消し線、および墨消しノードでは使用できません。
-
-
[イメージの傾き補正] - この設定を有効にすると、曲がってスキャンされたイメージは準備処理中に自動的に矯正されます。既定値は「有効」です。
-
[ファクス補正] - この設定を有効にすると、FAXイメージの解像度が2倍になります。既定値は「有効」です。
注: [イメージのノイズ除去] 、 [イメージの傾き補正]、または [ファクス補正] の前処理オプションをオフにすると、OCR処理が失敗する場合があります。これらのオプションをオフにした場合、ドキュメントを適切に処理できるようにワークフローに「ノイズ除去」ノードや、「傾き補正」ノードを追加する必要があります。
-
[ネガポジ反転] - OCRを実行する前に、暗い背景に対して白いテキストを含むイメージを準備処理中に一時的に反転して、OCR結果の精度を高めることができます。オプションは次のとおりです。
-
[自動] - この設定を有効にすると、イメージ反転の必要性が検出され、前処理中に反転が実行されます。既定値は「有効」です。
-
[すべてのイメージを反転] - この設定を有効にすると、すべてのイメージが自動的に反転され、検出手順がスキップされます。
-
[ネガポジ反転を適用しない] - この設定を有効にすると、OCR処理が開始される前に入力イメージは反転されません。このオプションを有効にすると、OCR結果の精度が影響を受ける可能性があることに注意してください。
-
-
[イメージ解像度の向上] - 入力イメージの解像度は、OCR処理の精度を向上させるために、準備処理中に一時的に向上させることができます。オプションは次のとおりです。
-
[160 dpi以下のすべてのイメージの解像度を上げる] - この設定を有効にすると、イメージの解像度が検出され、160dpi以下の場合は2倍になります。既定値は「有効」です。
-
[イメージの解像度を倍にする] - この設定を有効にすると、イメージの解像度が自動的に2倍になり、検出手順がスキップされます。
-
[イメージの解像度を上げない] - この設定を有効にすると、元のイメージの解像度は変更されません。このオプションを有効にすると、OCR結果の精度が影響を受ける可能性があることに注意してください。
-
回転
OCRを実行する前に、向きが正しくないページが検出され、修正が試みられます。入力ファイルの向きの誤りをすでに正確に把握しており、この自動検出処理を回避して処理時間を短縮したい場合は、ここで特定のオプションを選択できます。
-
[自動画像回転] - このオプションを有効にすると、OCRの実行前に入力画像の向きが検出され、不適切な向きのページ画像が自動的に回転します(90度、180度、または270度)。この[有効]オプションは回転と反転の既定値です。このチェックボックスをオフにすると、処理ノードウィンドウの「自動画像回転」オプションもオフになります。
-
[イメージを右に90°回転] - この設定を有効にすると、不適切な向きのページ画像が時計回りに90度回転します。
-
[イメージを左に90°回転] - この設定を有効にすると、不適切な向きのページ画像が反時計回りに90度回転します。
-
[イメージを180°回転] - この設定を有効にすると、不適切な向きのページ画像が上下が反転されます。
-
[イメージを回転しない] - この設定を有効にすると、画像は回転しません。
認識タブ
OCRの精度と処理時間を改善するために、認識処理を支援する特定の設定を指定できます。
注: このタブで使用できるオプションのセットは、エンジンの特徴/機能に基づいて、 OCR エンジン によって決定されます。オプションがタブに表示されない場合、そのオプションはOCRエンジンでサポートされていません。以下の図は、OmniPageおよびTesseract OCRエンジンで使用可能なオプションを示しています。各OCRエンジンで使用可能な言語を含むすべてのオプションは、図の下のセクションで説明されています。
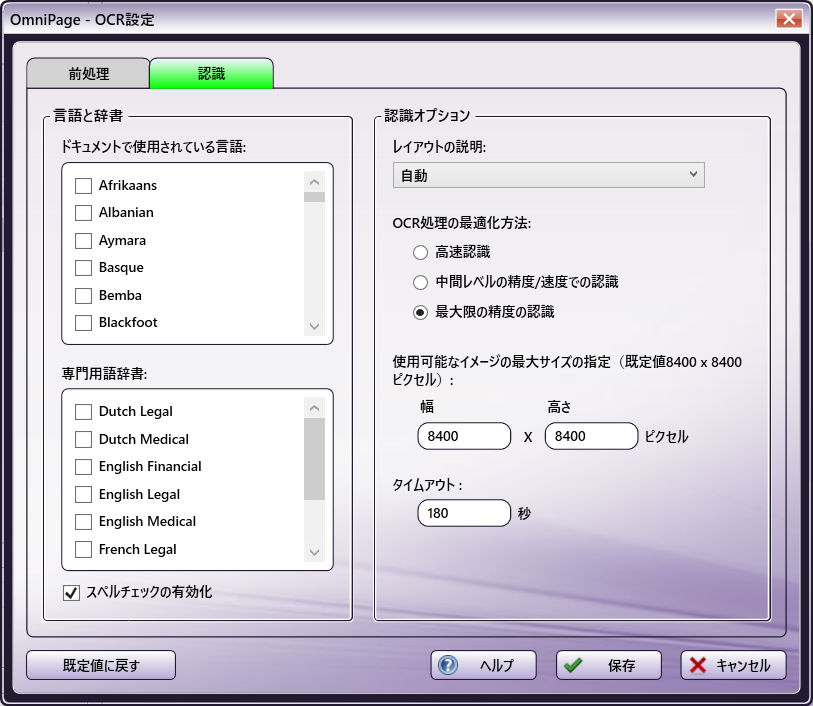
OmniPageオプション
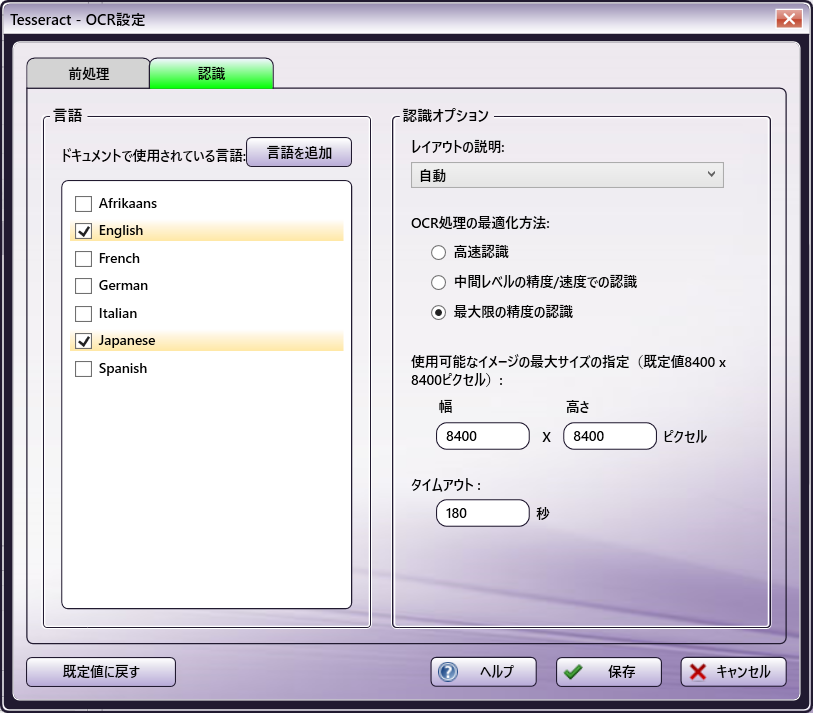
Tesseractオプション
言語と辞書
-
[ドキュメントで使用されている言語] - このウィンドウには、現在システムにロードされているすべての言語が表示されます。OCR認識処理に含める言語の横にあるチェックボックスをオンにします。複数の言語を選択することができますが、少なくとも1つ選択する必要があります。このフィールドの既定の設定は、オペレーティングシステムの既定の言語を反映しています。
- [言語を追加] - このオプションは、Tesseract OCRエンジンにのみ表示されます。既定のTesseract言語は、ドキュメントの「言語」ウィンドウに表示されます。Tesseract OCR認識処理にその他の言語を含めるには、このボタンをクリックします。「言語を追加」ウィンドウが表示されます。含める言語の横にあるチェックボックスをオンにして、 [インストール] ボタンをクリックします。一度に最大5つの言語をインストールすることができます。インストールが完了すると、選択した言語がドキュメントの「言語」ウィンドウに表示されます。
-
[専門用語辞書] - このパネルは、OmniPage OCRエンジンの場合にのみ表示されます。利用可能な専門用語辞書が一覧表示されます。複数の辞書を選択することができます。OmniPage OCR認識処理中に使用したい辞書の横にあるチェックボックスをオンにします。次の表に、使用可能な辞書の種類とそれぞれサポートされている言語を示します。
辞書 Dutch(オランダ語) English(英語) French(フランス語) German(ドイツ語) Financial N Y N N Legal Y Y Y Y Medical Y Y Y Y -
[スペルチェックの有効化] - このオプションは、OmniPage OCRエンジンでのみ使用できます。OCR認識中にスペルチェックを有効にするには、このボックスをオンにします。
この設定を有効にすると、OmniPage OCRエンジンのスペルチェッカーが認識できない単語を推定します(通常、低解像度のスキャンで)。スペルチェックの見積もりは単語の長さを変更しないことに注意してください。たとえば、「optica」は「optical」に変更されません。この設定を無効にすると、専門用語辞書リストが非アクティブになり、辞書を選択できなくなります。
OmniPage OCR言語
次の表に、OmniPage OCR エンジンでサポートされている言語を示します。
| 言語 | 言語 | 言語 | 言語 | 言語 |
|---|---|---|---|---|
| Afrikaans | Albanian | *Arabic | Aymara | Basque |
| Bemba | Blackfoot | Breton | Bugotu | Bulgarian (Cyrillic) |
| Byelorussian (Cyrillic) | Catalan | Chamorro | Chechen (Cyrillic) | Chuana (Tswana) |
| Corsican | Croatian | Crow | Czech | Danish |
| Dutch | English | Eskimo | Esperanto | Estonian |
| Faroese | Fijian | Finnish | French | Frisian |
| Friulian | Gaelic Irish | Gaelic Scottish | Galician | Ganda or Luganda |
| German | Greek | Guarani | Hani | Hawaiian |
| *Hebrew | Hungarian | Icelandic | Ido | Indonesian |
| Interlingua | Italian | *日本語 | Kabardian (Cyrillic) | Kashubian |
| Kawa | Kikuyu | Kongo | *Korean | Kpelle |
| Kurdish | Latin | Latvian | Lithuanian | Luba |
| Lule Sami | Luxembourgian | Macedonian (Cyrillic) | Malagasy | Malay |
| Malinke | Maltese | Maori | Mayan | Miao |
| Minangkabau | Mohawk | Moldavian (Cyrillic) | Nahuatl | Northern Sami |
| Norwegian | Nyanja | Occidental | Ojibway | Papiamento |
| Pidgin | Polish | Portuguese | Portuguese (Brazilian) | Provencal |
| Quechua | Rhaetic | Romanian | Romany | Ruanda |
| Rundi | Russian (Cyrillic) | Sami | Samoan | Sardinian |
| Serbian (Cyrillic) | Serbian (Latin) | Shona | *Simplified Chinese | Sioux |
| Slovak | Slovenian | Somali | Sotho | Southern Sami |
| Spanish | Sundanese | Swahili | Swazi | Swedish |
| Tagalog | Tahitian | *Thai | Tinpo | Tongan |
| *Traditional Chinese | Tun | Turkish | Ukrainian (Cyrillic) | Vietnamese |
| Visayan | Welsh | Wend | Wolof | Xhosa |
| Zapotec | Zulu |
* 言語をアクティブ化する前に、Asian FontPack(アジアンフォントパック)アドインを購入してインストールする必要があります。
Tesseract OCR言語
次の表に、Tesseract OCRエンジンでサポートされている言語を示します。
| 言語 | 言語 | 言語 | 言語 | 言語 |
|---|---|---|---|---|
| Afrikaans | Albanian | Amharic | Ancient Greek | Arabic |
| Armenian | Assamese | Azerbaijani | Azerbaijani - Cyrilic | Basque |
| Belarusian | Bengali | Bosnian | Breton | Bulgarian |
| Burmese | Catalan | Cebuano | Cherokee | Corsican |
| Croatian | Czech | Danish | Dutch | Dzongkha |
| English | Esperanto | Estonian | Faroese | Filipino |
| Finnish | French | Gaelic Irish | Galician | Georgian |
| German | Gujarati | Haitian | Hebrew | Hindi |
| Hungarian | Icelandic | Indonesian | Inuktitut | Italian |
| 日本語 | Javanese | Kannada | Kazakh | Khmer |
| Korean | Kurmanji | Kyrgyz | Lao | Latvian |
| Lithuanian | Luxembourgish | Macedonian | Malay | Malayalam |
| Maltese | Maori | Marathi | Middle English | Middle French |
| Modern Greek | Mongolian | Nepali | Norwegian | Occitan |
| Oriya | Pashto | Persian | Polish | Portuguese |
| Punjabi | Quechua | Romanian | Russian | Sanskrit |
| Scottish Gaelic | Serbian | Serbian - Latin | Simplified Chinese | Sindhi |
| Sinhala | Slovak | Slovenian | Spanish | Sundanese |
| Swahili | Swedish | Syriac | Tajik | Tamil |
| Tatar | Telugu | Thai | Tibetan | Tigrinya |
| Tongan | Traditional Chinese | Turkish | Uighur | Ukrainian |
| Urdu | Uzbek | Uzbek - Cyrilic | Vietnamese | Welsh |
| Western Frisian | Yiddish | Yoruba |
認識オプション
OCR処理中のテキストの認識を向上させるために、レイアウトの処理方法を反映して、元のドキュメントのレイアウトの説明を提供することができます。
[レイアウトの説明]
-
[自動] - レイアウトを自動検出するには(たとえば、テキストが列にあるかどうかなど)このオプションを選択します。このオプションによって、処理時間を最速にすることができます。このオプションは次のような場合に役立ちます。
-
ドキュメントをすばやく処理したい。
-
ドキュメントにレイアウトが異なる/不明なページが含まれている。
-
ドキュメントに複数の列と表を持つページがある。
-
ドキュメントに複数の表を含むページがある。
注: フォームが自動的に検出されることはありません。OCRフォームを検出するには、レイアウトとして フォーム を選択します。
-
-
[1列、表なし] - ページに次のいずれかが含まれている場合、この設定を有効にします。
- 1つの列で、表はなし(例:ビジネスレターや本のページ)。
- 1つの列に編成する必要がある列に配置された単語または数字。
-
[複数列、表なし] - 元のレイアウトと同様に、ページの列にテキストが含まれていて、別々の列に保持する必要がある場合は、この設定を有効にします。表のようなデータが検出された場合、グリッドテーブルではなく列に配置されます。
-
[1列、表あり] - ページに1列のテキストと1つの表しかない場合は、この設定を有効にします。
-
[スプレッドシート] - ページにスプレッドシートプログラムにエクスポートする表が含まれている場合、または表として扱われる場合は、この設定を有効にします。
-
[フォーム] - ページにフォームが含まれている場合は、この設定を有効にします。フォームオブジェクトと要素が検出されます。
-
[法律的訴答] - ページに法的弁論番号が含まれている場合は、この設定を有効にします。有効にすると、次のオプションが使用可能になります。
-
[法律的訴答番号の削除] - このオプションを選択して、受信ドキュメントからすべての法律的訴答番号を削除します。
-
[法律的訴答番号を保持] - このオプションを選択すると、受信ドキュメントにすべての法律的訴答番号が保持されます。この場合、番号は表示、編集、および検索可能になります。
-
-
[OCR処理の最適化方法]:
-
[高速認識] - この設定を有効にすると、認識処理の速度が最適化されます。この設定では精度が最も低くなりますが、受信するドキュメントの品質が高く、許容できる正確な結果が得られることがわかっている場合に役立ちます。この設定を有効にすると、色付きのテキスト/背景や反転したテキストなどの高度な書式設定が保持されない場合があります。
-
[中間レベルの精度/速度での認識] - この設定を有効にすると、迅速な処理と正確な結果のバランスが取れます。
-
[最大限の精度の認識] - この設定を有効にすると、認識処理が最適化され、正確になります。
-
-
[使用可能なイメージの最大サイズの指定] - 入力イメージの [幅] と [高さ] の制限(ピクセル単位)を設定します。これらの指定された値を超えるすべての入力イメージは処理されません。既定値は8400x8400ピクセルです。
-
[タイムアウト] - OCR認識処理がタイムアウトするまでの経過時間を秒単位で指定します。
出力タブ
OCR処理の出力の設定を指定することもできます。出力タブは、ドキュメントを別の形式に変換するノードに対してのみ表示されることに注意してください。さらに、高度なOCRノードからこのウィンドウにアクセスし、出力オプションとして「元のドキュメント+メタデータ」を指定した場合、このタブは表示されません。
注: このタブで使用できるオプションのセットは、エンジンの特徴/機能に基づいて、 OCR エンジン によって決定されます。オプションがタブに表示されない場合、そのオプションはOCR エンジンでサポートされていません。以下の図は、OmniPageおよびTesseract OCR エンジンで使用可能なオプションを示しています。すべてのオプションは、図の下のセクションで説明されています。
OmniPageオプション
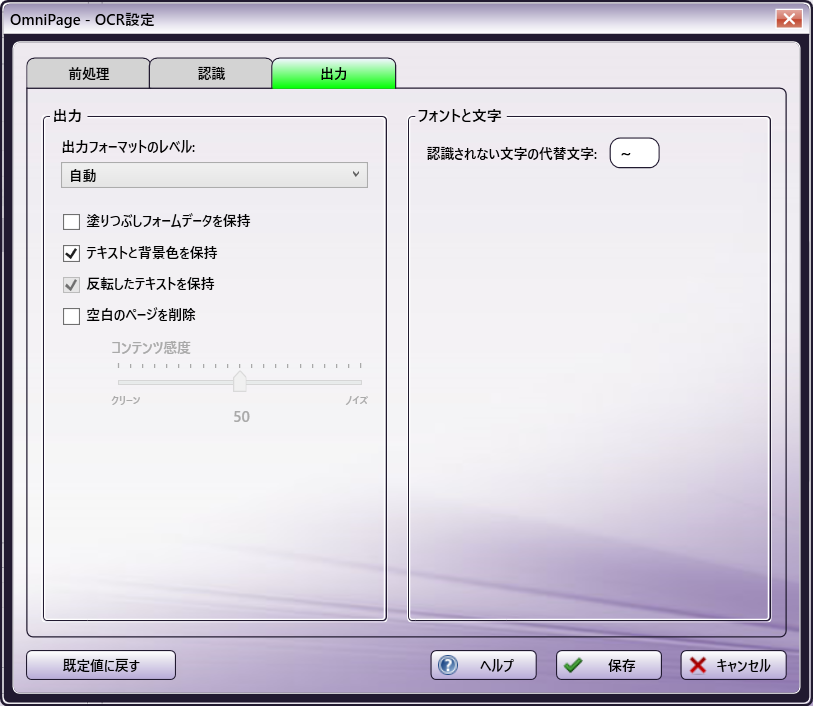
Tesseractオプション
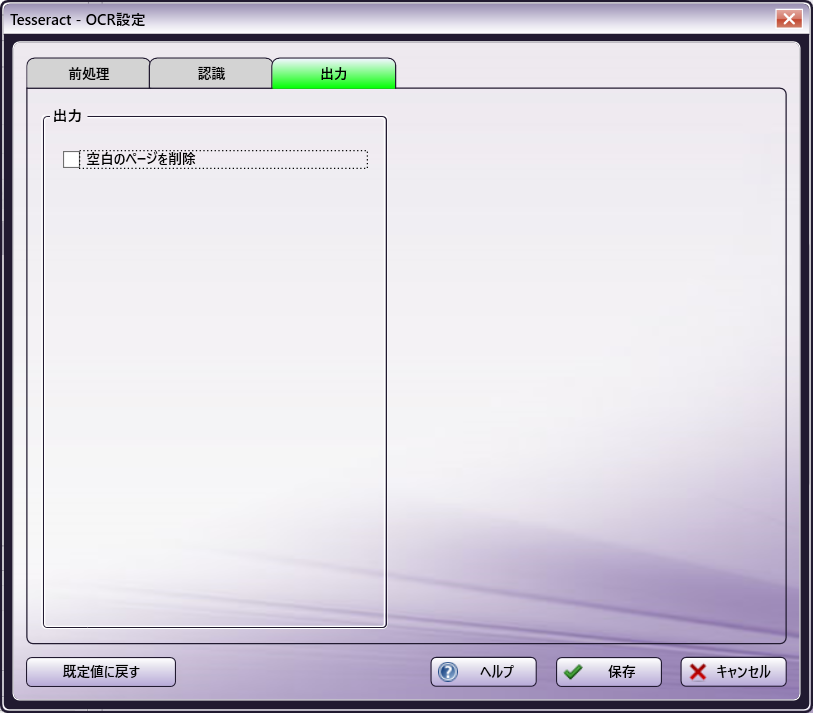
出力
-
[出力フォーマットのレベル]
-
[自動] - この設定を有効にすると、OCRエンジンは指定または検出されたレイアウトに基づいて、使用する出力形式を自動的に決定します。
-
[プレーンテキスト] - この設定を有効にすると、OCR処理は左揃えのプレーンなテキストを1つの列に出力します。
-
[フォーマット済みテキスト] - この設定を有効にすると、OCR処理はグラフィックスと表とともに、フォントと段落のスタイルを含むテキストを出力します。
注: Excelファイルとして保存する場合、ドキュメント内で検出された表やスプレッドシートはそれぞれ別のワークシートに保存されます。
-
[Trueページ] - この設定を有効にすると、列を含むページの元のレイアウトが、テキスト、イメージ、表のボックスとフレームを使用して出力時に保持されます。
-
[ページフロー] - この設定を有効にすると、段落を含むページの元のレイアウトが(テキストボックスやフレームの代わりに)可能な限り段落とインデント設定を使用して出力時に保持されます。テキストは段から段へ流し込まれます。
-
[スプレッドシート] - この設定を有効にすると、表計算アプリケーションでの使用に適した表の形式で結果が出力されます。各ページは別々のワークシートに配置されます。
-
-
[塗りつぶしフォームデータを保持] - この設定を有効にすると、塗りつぶされたフォームデータは変換処理中も保持されます。 このボックスは既定ではチェックされていません。
-
[テキストと背景色を保持] - この設定を有効にすると、色付きのテキストと背景が検出されて出力に使用されます。ドキュメントにカラー写真は必要であるが、色付きのテキスト/背景が必要ない場合はこの設定を無効にしてください。 このボックスは既定でチェックされています。
-
[反転したテキストを保持] - このオプションを有効にすると、色反転テキスト(黒または濃い色の背景に白または淡い色の文字)が出力で保持されます。色反転テキストを通常のテキストに変換するには、この設定を無効にします。 OCR処理の最適化方法 オプションを設定した場合、このオプションは使用できません。
-
[空白のページを削除] - この設定を有効にすると、空白のページは出力ファイルに含まれません。 このボックスは既定ではチェックされていません。
- [コンテンツ感度] - 空白ページのマークや傷に対する感度のしきい値を指定します。
- クリーン - スライダーをクリーン(100)の方向に動かして、感度のしきい値を上げます。
- ノイズ - スライダーをノイズ(0)の方向に動かして、感度のしきい値を下げます。
- [コンテンツ感度] - 空白ページのマークや傷に対する感度のしきい値を指定します。
Dispatcher Phoenixでサポートされている出力フォーマット/タイプ
| 出力フォーマット/タイプ | プレーンテキスト | フォーマット済テキスト | スプレッドシート | Trueページ | ページフロー |
|---|---|---|---|---|---|
| eBook | YES | YES | NO | NO | NO |
| Microsoft Excel | YES | YES | YES | NO | NO |
| Microsoft PowerPoint / Microsoft Publisher | YES | YES | NO | NO | NO |
| Microsoft Word | YES | YES | NO | YES | YES |
| NO | NO | NO | YES | NO | |
| 編集済みPDF | YES | YES | NO | YES | NO |
| テキスト上の画像またはイメージ置き換え付きのPDF | NO | NO | NO | YES | NO |
| RTF Word 2000 | YES | YES | NO | YES | YES |
| WordPad | YES | YES | NO | NO | NO |
| WordPerfect 9, 10 | YES | YES | NO | YES | YES |
| XML Paper Specification (XPS) | NO | NO | NO | YES | NO |
注: すべての出力形式の既定のオプションは「自動」です。
フォントと文字
[認識されない文字の代替文字] - 既定では、OCRエンジンによって検出された認識できない文字は、出力で「赤いチルダ文字(〜)」で表されます。たとえば、OCR処理が「reject」の「j」を認識できなかった場合、出力は「re~ect」のようになります。このフィールドで、使用する独自の文字を指定することができます。
バーコードエンジン
光学式文字認識はOCRエンジンによって駆動されます。Dispatcher Phoenixは現在、次のOCRエンジンをサポートしています。
ZXingノード
次のノードはZXingバーコードエンジンをサポートします。
- 2Dバーコード処理 - 2Dバーコード処理ノードは、ZXingエンジンのサポートを含むDispatcher Phoenix基本ライセンスに含まれています。OmniPageのサポートは個別に購入することができます。 ZXingエンジンの詳細設定について は、以下で詳しく説明します。
- バーコード処理 - バーコード処理ノードは、ZXingエンジンのサポートを含むDispatcher Phoenix基本ライセンスに含まれています。OmniPageのサポートは個別に購入することができます。 ZXingエンジンの詳細設定について は、以下で詳しく説明します。
ZXingの高度な設定

ZXingバーコードエンジンの詳細オプションは次の通りです。
- [バーコードスキャン処理を最適化]: - この設定は、エンジンがバーコードをスキャンする方法を制御します。
- [精度] - この設定を有効にすると、認識処理を最適化して精度を高めます。
- [パフォーマンス] - この設定を有効にすると、認識処理を速度に合わせて最適化することができます。この設定では結果の精度が低下する可能性がありますが、受信したドキュメントの品質が良好で、許容範囲内で正確な結果が得られることがわかっている場合に有効です。
- [ゾーンを回転してバーコードを検出] - バーコードをスキャンする前に、アプリケーションはバーコード検出用のゾーンを検出し、正しい方向に向けようとします。受信ファイルの正確な位置ずれがすでにわかっていて、この自動検出処理を回避して処理時間を短縮したい場合は、ここで特定のオプションを選択することができます。
- [スキャン中にゾーンを90度、180度、および270度回転] - この設定を有効にすると、ゾーンの方向が検出され、OCRが実行される前に不適切な向きのページ画像が自動的に回されます(90度、180度、または270度)。このオプションは回転と反転で既定で有効です。
- [イメージを回転しない] - この設定を有効にすると、画像は回転されません。
- [ゾーンを反転してバーコードを検出] - バーコードをスキャンする前に、準備処理中に暗い背景に対して白いテキストの画像を 一時的に 反転させて、OCR結果の精度を向上させることができます。
- [スキャン中にゾーンを反転] - この設定を有効にすると、色反転の必要性が検出され、前処理中にゾーンで反転が実行されます。このオプションは既定で有効です。
- [ゾーンを反転しない] - この設定を有効にすると、ゾーンはOCR処理が開始される前に反転されません。このオプションを有効にすると、OCR結果の精度が影響を受ける場合があります。
- [ゾーンをダウンスケールして処理速度を向上] - この設定では、エンジンが大きなファイルのバーコードをスキャンする方法を制御します。
- [バーコード検出を試行する前にゾーンをダウンスケール] - この設定を有効にすると、エンジンはバーコードを検出するために 一時的に ゾーンをダウンサイズしようとします。これにより、パフォーマンスが向上する可能性があります。
- [ゾーンをダウンスケールしない] - この設定を有効にすると、ゾーンはスキャン前にダウンスケールされません。