Overview of Parsing
Parsing is a process performed on files based on pre-defined rules. A Parser Rule is a process within a workflow that performs a Search For, Distribute, Insert, or Replace operation, based on the conditions you define. Prior to setting up a Parser process, you need to configure a Parser Rule Node.
For a Rule Node, you can define the following:
-
Search words or phrases.
-
Search starting and end points (Search From and Search To).
-
Any text to be inserted or replaced at a specified location within the file.
Note: When defining line numbers as your search’s starting and end points, be aware that the search will not include the ending line number. For example, if you create a Parse and Insert process that searches for a specific text string from Line Number 4 to Line Number 7, the search results will not include Line Number 7.
You can create multiple Rule Sets to apply to a text file, and each rule may have different words or phrases to be “Searched for” and “Inserted/Replaced,” if each Rule is met. If you are familiar with printer description languages, such as PostScript and/or PCL, you can even create a rule that will modify the input file, and instruct a Konica Minolta MFP to perform a specific operation on that file.
There are four graphical nodes to represent the different types of Parser Rules:
-
Parse - Used to create a Search rule only, to be followed by another process.
-
Parse & Insert - Used to insert a text string after finding the object of a Search.
-
Parse & Replace - For replacing text found by a Search rule.
-
Parse & Distribute - Can be used to search for a keyword or text string within a file, not just in the file name, type or size, but to search the content of the file (metadata).
All Previous Occurrences Example
The Parse & Insert, Parse & Replace, and Parse & Distribute nodes offer a “All Previous Occurrences” search option. This ability to perform a secondary search on the results of a previous search is extremely useful and will give you the ability to perform complex operations using substantially shorter rules.
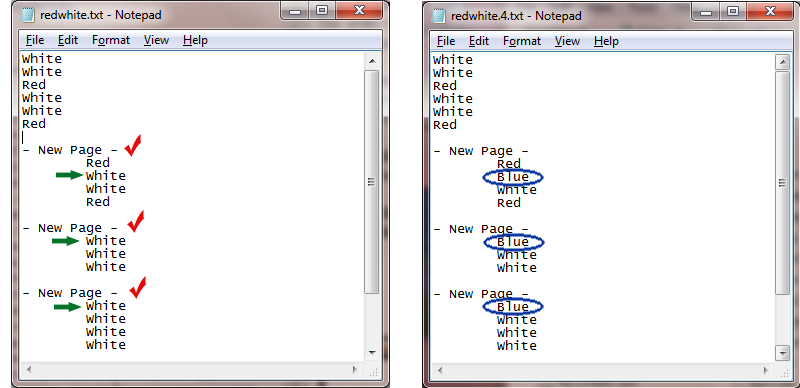
In this example, certain occurrences of the word “white” in a text file need to be changed to “blue.” Sounds simple? In most cases, you could use the Parse & Replace node to perform this operation (specifying “white” in the Search area and “blue” in the Replace area). However, in this case, the only time “white” needs to be changed is when it is the first occurrence in a subset of the phrase “- New Page - .”
Your workflow would consist of a Parse & Distribute node searching for “- New Page - " followed by a Parse & Replace node searching for “White” in all previous search occurrences up to the first occurrence and replacing “White” with “Blue” in all occurrences.
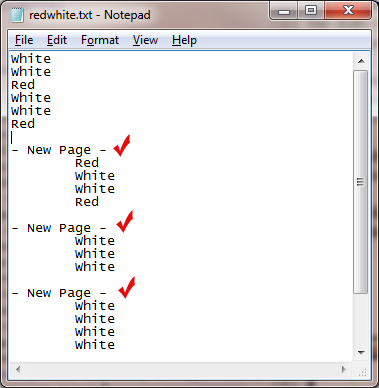
Step #1: Define a search for “- New Page - " using the Parse & Distribute node, as follows:

This search looks for each instance of “- New Page -” within the file. In the following illustration, a red check mark identifies the results of that search:
Step #2: Define a search and replace using the Parse & Replace node, as follows:
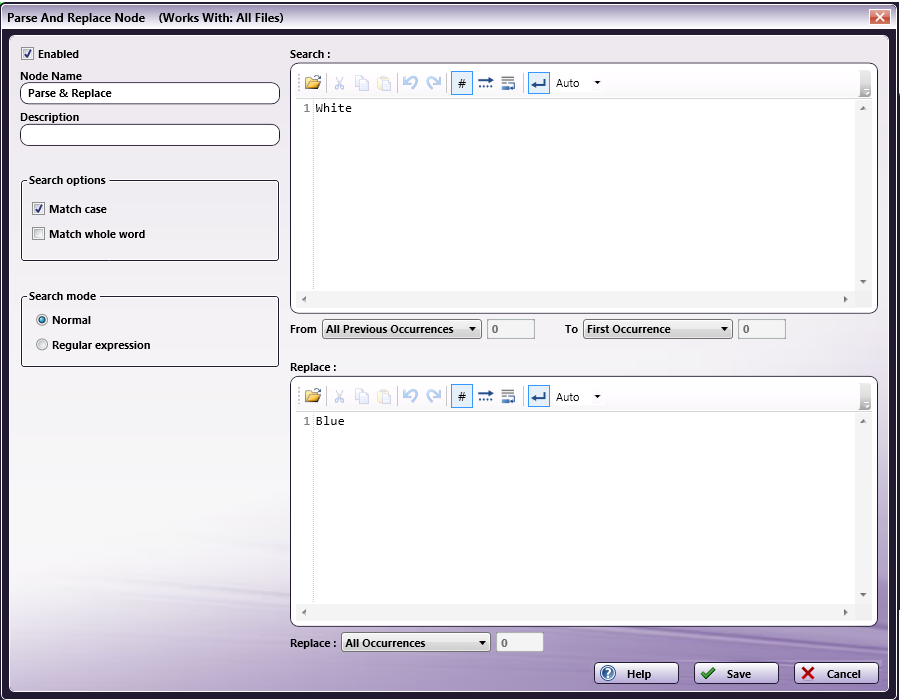
The Search operation will look through the content of each group that was found in the previous Parse & Distribute search. When the first occurrence of “White” in each group is found, it is replaced with “Blue.” In the illustration on the left, a green arrow identifies the results of the search (starting from “All Previous Occurrences” to the “First Occurrence”). In the illustration on the right, the results of the “All Occurrences” replace operation are circled in blue: