PDF Data Extraction

The PDF Data Extraction process is an optional node that extracts metadata from incoming PDF files for future use by other nodes in the workflow (i.e., routing on specific Document Properties, etc.) or for import into other systems for search purposes. With this process, the user must specify what metadata to extract. Files that cannot be opened as PDFs will leave this node on an “Error” transition.
Important! Metadata extracted from the PDF Data Extraction node is case sensitive. When using the metadata in your workflow, make sure that you use the appropriate case.
Sample Use Case: When batch processing PDF forms, data from the fields in the forms needs to be extracted and inserted into a database. A workflow that collects files from an Input Folder, processes them through the PDF Data Extraction and ODBC Processing nodes, and distributes them to an Output Folder automates this process.
Note: This node does not support AES (Advanced Encryption Standard) PDFs.
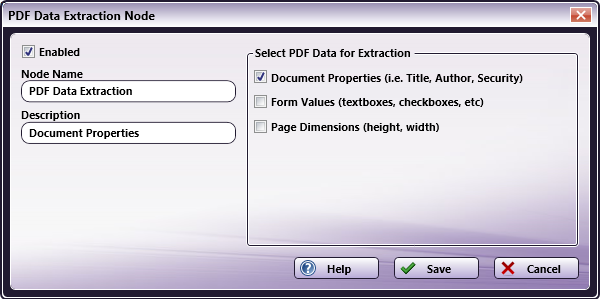
To open the PDF Data Extraction window, add a process node for PDF Data Extraction and double-click on it.
-
Check the Enabled box when there are multiple processes in a workflow. If unchecked, this process will be ignored. Documents will pass through as if the node was not present. Note that a disabled node will not check for logic or error conditions.
-
In the Node Name field, enter a meaningful name for the PDF Data Extraction node.
-
In the Description field, enter a description for the PDF Data Extraction node. Although this is not required, it can be helpful to distinguish multiple processes from each other. If the description is long, you can hover the mouse over the field to read its entire contents.
-
The Select PDF Data for Extraction area allows you to choose what PDF metadata should be extracted from the incoming document.
Note: Only Document Properties and Page Dimensions metadata will be listed in the Metadata Browser window for use by other nodes in the workflow.
You can choose to extract:
-
Document Properties – Information about the PDF, including the author, creator, subject, title, keywords, version, pages, and security options (whether or not it is encrypted, editable, printable, and enabled for high resolution printing).
-
Form Values - The values of form fields, such as text boxes, check boxes, radio buttons, etc. Values for PDF buttons are not extracted since buttons only have actions and labels associated with them (rather than values). Note that form values can only be extracted from PDF forms that have been created electronically and shared electronically. This means that Form values cannot be extracted from paper forms that have been scanned from the MFP as a PDF file type. To extract values from PDF image files, you must use the Advanced OCR node.
-
-
Page Dimensions – The height and width of the document.
- Select the Save button to keep your PDF Data Extraction definition. You can also select the Help button to access online help and select the Cancel button to exit the window without saving any changes.
Important! Metadata from the PDF Data Extraction node is not inherently saved. Users must add an additional node, such as the Metadata to File to a workflow in order to capture the data extracted.