OCR and Barcode Settings
This topic describes the OCR Settings window. This window is available in Dispatcher Phoenix nodes that support optical character recognition (OCR). These nodes contain the Advanced Settings button (sometimes called the Advanced OCR Settings button), which accesses the OCR Settings window. See the illustration below:
Note: This page primarily applies to Tesseract and OmniPage. Settings for the ZXing barcode engine are explained below.
OCR Engines
Optical character recognition is driven by an OCR engine. Dispatcher Phoenix currently supports the following OCR engines:
- Tesseract
- OmniPage
Each OCR-capable node supports one or more OCR engines. If the node supports only one OCR engine, that engine defaults. For nodes that default to Tesseract, the OCR Engine field in the node’s Properties window displays “Tesseract”. However, for nodes that do not support Tesseract, OmniPage defaults but the OCR Engine field does not display “OmniPage”.
If the node supports multiple engines, and you have licensed multiple engines, the OCR Engine field in the node includes a drop-down menu and you can select an engine.
When you access the OCR Settings window, the set of options that is available is determined by the OCR engine, based on the functional capabilities of the engine.
Note: For OCR-capable nodes, the OCR engine can also affect the list of output options that are available at the Output field in the node’s Properties window.
OCR-Capable Nodes
The following Dispatcher Phoenix process nodes are equipped with OCR capability:
- 2D Barcode Processing
- Advanced OCR
- Barcode Processing
- Convert to PDF
- Convert to Office
- Doc-Classifier
- Forms Processing
- Highlight/Strikeout
- Redact
OmniPage Nodes
All OCR-capable nodes support the OmniPage OCR engine. These nodes must be purchased as add-in nodes to the Dispatcher Phoenix base license or as part of a Dispatcher Phoenix vertical market package, with the following exceptions:
- Advanced OCR - Advanced OCR is included in the Dispatcher Phoenix base license. It includes support for the Tesseract and OmniPage. OmniPage for Advanced OCR is available as a separate purchase.
- Convert to PDF - Convert to PDF is included in the Dispatcher Phoenix base license. It includes support for Tesseract. OmniPage for Convert to PDF is available as a separate purchase.
Important! When using the OmniPage OCR engine to scan languages other than English, optimal results are returned when scanned strings contain 3 or more characters and each character is between 30x30 and 48x48 px.
All barcode-capable nodes support the OmniPage barcode engine:
- 2D Barcode Processing - 2D Barcode Processing is included in the Dispatcher Phoenix base license with the ZXing barcode engine. 2D Barcode Processing with OmniPage is available as an add-in node.
- Barcode Processing - Barcode Processing is included in the Dispatcher Phoenix base license with the ZXing barcode engine. Barcode Processing with OmniPage is available as an add-in node.
Tesseract Nodes
The following nodes support the Tesseract OCR engine:
- Advanced OCR - Advanced OCR is included in the Dispatcher Phoenix base license. It includes support for Tesseract.
- Convert to PDF - Convert to PDF is included in the Dispatcher Phoenix base license. It includes support for Tesseract.
- Forms Processing - A purchase of the Forms Processing node includes support for the Tesseract and OmniPage.
Note: The Tesseract OCR engine includes an option to install additional languages for use in the OCR recognition process. These additional languages are included in the Tesseract OCR engine and require no additional licenses or purchases.
Multiple OCR Engine Nodes
This section contains a table for each Dispatcher Phoenix node that supports both the OmniPage and Tesseract OCR engines. The table lists the Dispatcher Phoenix functions and features supported by each OCR engine.
Advanced OCR Node - OCR Functionality Table
| OCR Feature/Function | OmniPage | Tesseract |
|---|---|---|
| Autozone | Yes | Yes |
| Page Range to Process | Every page Every even page Every odd page First page Last page Define your own page range |
Every page Every even page Every odd page First page Last page Define your own page range |
| Output | Original document + Metadata PDF Searchable PDF with image substitutes Microsoft Word 2000 XP (*.doc) Microsoft Word 2003 (WordML) Microsoft Word 2003 XP (*.xls) Microsoft Powerpoint 97 (*.ppt) XPS Searchable RTF Word 2000 Text Comma Separated Text Formatted Text Text with linebreaks Unicode Text Unicode Comma Separated Text Unicode Formatted Text Unicode Text with linebreaks XML eBook |
Original document + Metadata PDF Searchable Text Comma Separated Text Text with linebreaks Unicode Text Unicode Comma Separated Text Unicode Text with linebreaks |
| Advanced Settings | Yes | Yes |
| Pre-Process | Despeckle Deskew Fax Correction image Inversion Enhanced Image Resolution Rotation |
Deskew Rotation |
| Recognition | 127 Languages 9 Dictionaries Spell Check Layout Description: - Automatic - Single Column, no Table - Multiple Columns, no Table - Single Column with Table - Spreadsheet - Form - Legal Pleading Optimize OCR process Specify maximum image size Timeout |
113 Languages Layout Description: - Automatic - Single Column, no Table - Multiple Columns, no Table - Single Column with Table - Spreadsheet Optimize OCR process Specify maximum image size Timeout |
| OCR Settings Output | Output formatting level Retain filled form data Retain inverted text Retain text and background color Blank page removal Unrecognized character substitution |
None |
Convert to PDF - OCR Functionality Table
| OCR Feature/Function | OmniPage | Tesseract |
|---|---|---|
| File Type | PDF PDF edited PDF Image Only PDF Searchable PDF with image substitutes |
PDF Searchable PDF image only |
| PDF Version | Optimize for Quality Optimize for Size PDF 1.3 PDF 1.4 PDF 1.5 PDF 1.6 PDF 1.7 PDF/A-1a PDF/A-2a PDF/A-3a PDF/A-1b PDF/A-2b PDF/A-3b PDF/A-2u PDF/A-3u |
None |
| Remove Blank Pages | Yes | Yes |
| Auto-Rotate | Yes | Yes |
| Security Settings | Yes | Yes |
| Advanced Settings | Yes | Yes |
| Pre-Process | Despeckle Deskew Fax Correction image Inversion Enhanced Image Resolution Rotation |
Deskew Rotation |
| Recognition | 127 Languages 9 Dictionaries Spell Check Layout Description: - Automatic - Single Column, no Table - Multiple Columns, no Table - Single Column with Table - Spreadsheet - Form - Legal Pleading Optimize OCR process Specify maximum image size Timeout |
113 Languages Layout Description: - Automatic - Single Column, no Table - Multiple Columns, no Table - Single Column with Table - Spreadsheet Optimize OCR process Specify maximum image size Timeout |
| OCR Settings Output | Output formatting level Retain filled form data Retain inverted text Retain text and background color Blank page removal Unrecognized character substitution |
Blank page removal |
Forms Processing - OCR Functionality Table
| OCR Feature/Function | OmniPage | Tesseract |
|---|---|---|
| Run Rule Configuration | Yes | Yes |
| Advanced Settings | Yes | Yes |
| Pre-Process | Despeckle Deskew Fax Correction image Inversion Enhanced Image Resolution Rotation |
Deskew Rotation |
| Recognition | 127 Languages 9 Dictionaries Spell Check Layout Description: - Automatic - Single Column, no Table - Multiple Columns, no Table - Single Column with Table - Spreadsheet - Form - Legal Pleading Optimize OCR process Specify maximum image size Timeout |
113 Languages Layout Description: - Automatic - Single Column, no Table - Multiple Columns, no Table - Single Column with Table - Spreadsheet Optimize OCR process Specify maximum image size Timeout |
Using the Advanced OCR Settings Window
The Advanced OCR Settings window contains settings you can use to adjust the accuracy of the OCR results as well as the performance time of the OCR process.
The Advanced OCR Settings window contains the following tabs, each with a set of related settings. You can specify settings for:
-
Output format (this tab appears only for nodes that convert documents to another format)
Buttons
The following buttons are available from each tab in the OCR Settings window:
- Restore Defaults - To reset all customized settings to their default values, click this button.
- Help - To access Online Help for this window, click this button.
- Save - To preserve the current OCR Settings, click this button.
- Cancel - To exit the OCR Settings window without saving any changes and return to the node properties window, click this button.
Pre-process Tab
Use this tab to set parameters specifying how to prepare and pre-process images before OCR analysis and recognition begins.
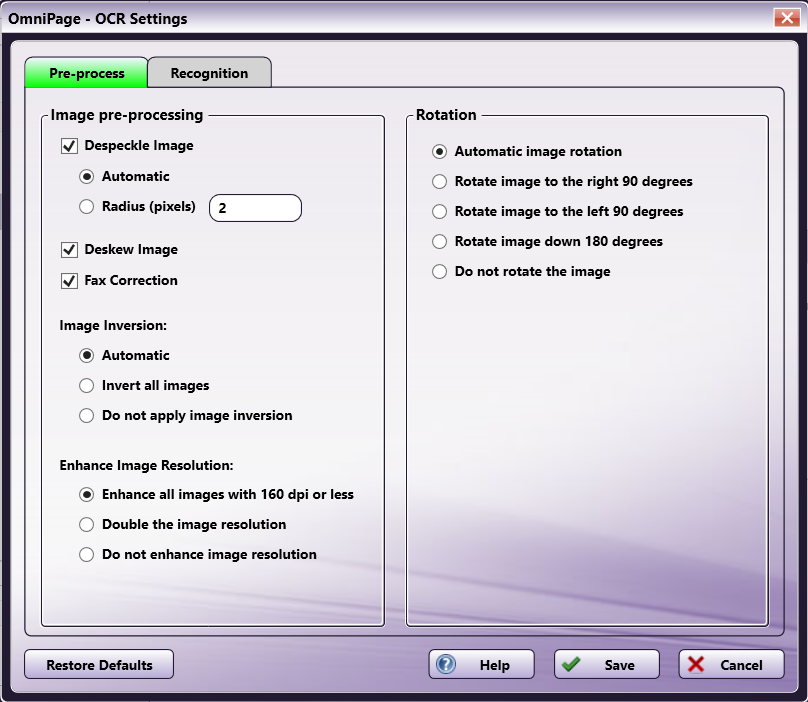
Note: The set of options available on this tab is determined by the OCR engine, based on the functional capabilities of the engine. If an option does not appear in the tab, it is not supported by the OCR engine. The illustrations below show the options available for the OmniPage and Tesseract OCR engines. All options are described in the section below the illustrations.
OmniPage Options
Tesseract Options
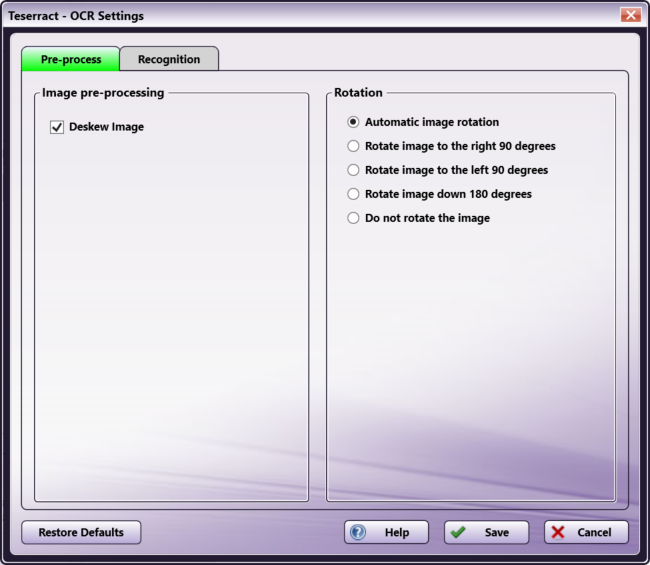
Image Pre-processing
Pre-processing procedures can be applied to images to enhance their quality before OCR recognition is performed. Enabling or disabling these options may improve the quality of your output and/or the performance time of the OCR process.
-
Despeckle Image - When this setting is enabled, images are automatically despeckled for OCR purposes during the preparation process. Although the OCR process tolerates low quality images, any spots or smudges should be removed from images for best results. Despeckle looks for “noise” on a scanned image and removes it. The default value is enabled.
-
Automatic - When this setting is enabled, the OCR engine automatically selects the pixel radius for despeckling.
-
Radius (Pixels) - When this setting is enabled, the user sets the pixel radius that the OCR engine uses for despeckling.
Note: This option is only available for the 2D Barcode Processing, Advanced OCR, Barcode Processing, Convert to PDF, and Forms Processing nodes. This option is not available for the Convert to Office, Doc-Classifier, Highlight & Strikeout, and Redact nodes.
-
-
Deskew Image - When this setting is enabled, images that have been scanned in crookedly are automatically straightened during the preparation process. The default value is enabled.
-
Fax correction - When this setting is enabled, the resolution of faxed images will be doubled. The default value is enabled.
Note: Turning off the pre-processing options Despeckle Image, Deskew Image, or Fax Correction may cause the OCR process to fail. If you turn off these options, you may need to add the Despeckle and/or Deskew nodes to the workflow so that the document can be properly processed.
-
Image Inversion - Before performing OCR, images with white text against a dark background can be temporarily inverted during the preparation process to increase the accuracy of the OCR results. Options can be:
-
Automatic - When this setting is enabled, the need for image inversion is detected and inversion is performed during pre-processing. This enabled option is the default value.
-
Invert all images - When this setting is enabled, all images are automatically inverted, skipping the detection step.
-
Do not apply image inversion - When this setting is enabled, incoming images are not inverted before the OCR process begins. Note that the accuracy of the OCR results may be affected with this option enabled.
-
-
Enhance Image Resolution - The resolution of incoming images can be temporarily enhanced during the preparation process to improve the accuracy of the OCR process. Options are:
-
Enhance all images with 160 dpi or less - When this setting is enabled, image resolutions are detected and doubled if 160 dpi or less. This enabled option is the default value.
-
Double the image resolution - When this setting is enabled, the image resolution is automatically doubled, skipping the detection step.
-
Do not enhance image resolution - When this setting is enabled, the original image resolution will not change. Note that the accuracy of the OCR results may be affected with this option enabled.
-
Rotation
Before performing OCR, the application tries to detect and correct incorrectly oriented pages. If you already know the exact misalignment of incoming files and want to speed up processing time by avoiding this auto-detection process, you can choose specific options here.
-
Automatic image rotation - When this setting is enabled, the orientation of incoming images is detected and improperly oriented page images are automatically rotated (by 90, 180, or 270 degrees) before OCR takes place. This enabled option is the default value for rotation and mirroring; if you uncheck this box, the Auto-Rotate option on the process node window will also be unchecked.
-
Rotate image to the right 90 degrees - When this setting is enabled, improperly oriented page images are rotated by 90 degrees, clockwise.
-
Rotate image to the left 90 degrees - When this setting is enabled, improperly oriented page images are rotated by 90 degrees, counter-clockwise.
-
Rotate image down 180 degrees - When this setting is enabled, improperly oriented page images are turned upside down.
-
Do not rotate the image - When this setting is enabled, the image is not rotated.
Recognition Tab
To improve OCR accuracy and processing time, you can specify specific settings to assist in the recognition process.
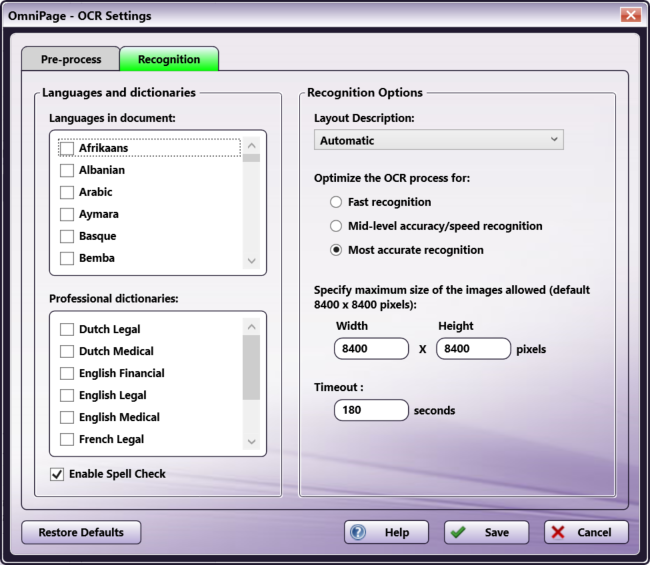
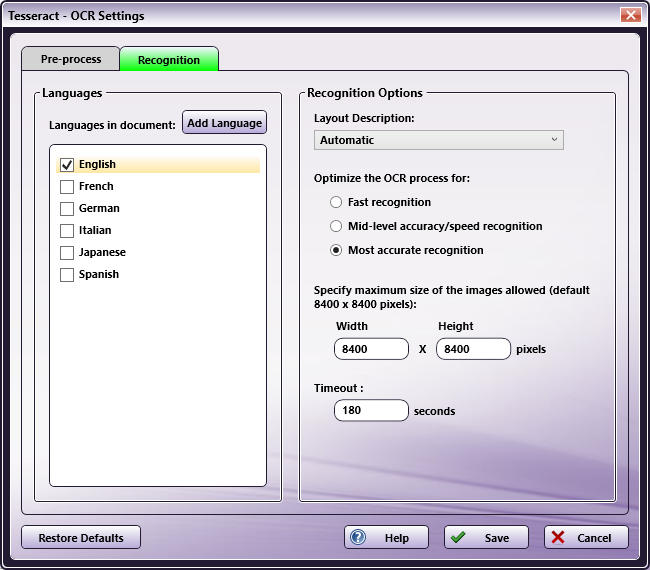
Note: The set of options available on this tab is determined by the OCR engine, based on the functional capabilities of the engine. If an option does not appear in the tab, it is not supported by the OCR engine. The illustrations below show the options available for the OmniPage and Tesseract OCR engines. All options, including the available languages for each OCR engine, are described in sections below the illustrations.
OmniPage Options
Tesseract Options
Languages and dictionaries
-
Languages in document - This window displays all languages currently loaded into your system. Check the box next to the languages you want to include in the OCR recognition process. You can select multiple languages, but you must select at least one. The default setting at this field reflects the default language for your operating system.
- Add Languages - This option appears only for the Tesseract OCR engine. The default Tesseract languages appear in the Languages in document window. To include other languages in the Tesseract OCR recognition process, click this button. The Add Language window appears. Check the box next to the languages you want to include, and click the Install button. You can install up to five languages at one time. When the installation is complete, the selected languages appear in the Languages in Document window.
-
Professional dictionaries - This panel appears only for the OmniPage OCR engine. It lists the available professional dictionaries. You can select multiple dictionaries. Check the box next to the dictionaries you want to use during the OmniPage OCR recognition process. The following table lists the available dictionary types and the languages supported for each.
Dictionary Dutch English French German Financial N Y N N Legal Y Y Y Y Medical Y Y Y Y -
Enable Spell Check - This option is available only for the OmniPage OCR engine. To enable spell checking during OCR recognition, check this box.
If you enable this setting, the spell-checker for OmniPage’s OCR engine estimates unrecognizable words (usually on lower resolution scans). Note that spell check estimations do not change the length of the word. For example, ‘optica’ will not be changed to ‘optical.’ If you disable this setting, the Professional Dictionaries list becomes inactive and you cannot choose a dictionary.
OmniPage OCR Languages
The following table lists the languages supported by the OmniPage OCR engine:
| Language | Language | Language | Language | Language |
|---|---|---|---|---|
| Afrikaans | Albanian | *Arabic | Aymara | Basque |
| Bemba | Blackfoot | Breton | Bugotu | Bulgarian (Cyrillic) |
| Byelorussian (Cyrillic) | Catalan | Chamorro | Chechen (Cyrillic) | Chuana (Tswana) |
| Corsican | Croatian | Crow | Czech | Danish |
| Dutch | English | Eskimo | Esperanto | Estonian |
| Faroese | Fijian | Finnish | French | Frisian |
| Friulian | Gaelic Irish | Gaelic Scottish | Galician | Ganda or Luganda |
| German | Greek | Guarani | Hani | Hawaiian |
| *Hebrew | Hungarian | Icelandic | Ido | Indonesian |
| Interlingua | Italian | *Japanese | Kabardian (Cyrillic) | Kashubian |
| Kawa | Kikuyu | Kongo | *Korean | Kpelle |
| Kurdish | Latin | Latvian | Lithuanian | Luba |
| Lule Sami | Luxembourgian | Macedonian (Cyrillic) | Malagasy | Malay |
| Malinke | Maltese | Maori | Mayan | Miao |
| Minangkabau | Mohawk | Moldavian (Cyrillic) | Nahuatl | Northern Sami |
| Norwegian | Nyanja | Occidental | Ojibway | Papiamento |
| Pidgin | Polish | Portuguese | Portuguese (Brazilian) | Provencal |
| Quechua | Rhaetic | Romanian | Romany | Ruanda |
| Rundi | Russian (Cyrillic) | Sami | Samoan | Sardinian |
| Serbian (Cyrillic) | Serbian (Latin) | Shona | *Simplified Chinese | Sioux |
| Slovak | Slovenian | Somali | Sotho | Southern Sami |
| Spanish | Sundanese | Swahili | Swazi | Swedish |
| Tagalog | Tahitian | *Thai | Tinpo | Tongan |
| *Traditional Chinese | Tun | Turkish | Ukrainian (Cyrillic) | Vietnamese |
| Visayan | Welsh | Wend | Wolof | Xhosa |
| Zapotec | Zulu |
* Requires a purchase and installation of the Asian Font Pack add-in before the language can be activated.
Tesseract OCR Languages
The following table lists the languages supported by the Tesseract OCR engine:
| Language | Language | Language | Language | Language |
|---|---|---|---|---|
| Afrikaans | Albanian | Amharic | Ancient Greek | Arabic |
| Armenian | Assamese | Azerbaijani | Azerbaijani - Cyrilic | Basque |
| Belarusian | Bengali | Bosnian | Breton | Bulgarian |
| Burmese | Catalan | Cebuano | Cherokee | Corsican |
| Croatian | Czech | Danish | Dutch | Dzongkha |
| English | Esperanto | Estonian | Faroese | Filipino |
| Finnish | French | Gaelic Irish | Galician | Georgian |
| German | Gujarati | Haitian | Hebrew | Hindi |
| Hungarian | Icelandic | Indonesian | Inuktitut | Italian |
| Japanese | Javanese | Kannada | Kazakh | Khmer |
| Korean | Kurmanji | Kyrgyz | Lao | Latvian |
| Lithuanian | Luxembourgish | Macedonian | Malay | Malayalam |
| Maltese | Maori | Marathi | Middle English | Middle French |
| Modern Greek | Mongolian | Nepali | Norwegian | Occitan |
| Oriya | Pashto | Persian | Polish | Portuguese |
| Punjabi | Quechua | Romanian | Russian | Sanskrit |
| Scottish Gaelic | Serbian | Serbian - Latin | Simplified Chinese | Sindhi |
| Sinhala | Slovak | Slovenian | Spanish | Sundanese |
| Swahili | Swedish | Syriac | Tajik | Tamil |
| Tatar | Telugu | Thai | Tibetan | Tigrinya |
| Tongan | Traditional Chinese | Turkish | Uighur | Ukrainian |
| Urdu | Uzbek | Uzbek - Cyrilic | Vietnamese | Welsh |
| Western Frisian | Yiddish | Yoruba |
Recognition Options
To improve recognition of text during the OCR process, you can provide a description of the original document’s layout, reflecting how you want the layout to be handled.
Layout Description
-
Automatic - To auto-detect the layout (e.g., whether text is in columns, etc.), select this option. This option allows for the speediest processing time. This option is useful if:
-
You want to process your documents quickly.
-
Your documents contain pages with different/unknown layouts.
-
Your documents have pages with multiple columns and a table.
-
Your document have pages containing more than one table.
Note: Forms are never automatically detected. To detect OCR forms, select Form as the layout.
-
-
Single Column, no Table - Enable this setting if your pages contain any of the following:
- One column and no tables (e.g., business letters or pages from a book).
- Words or numbers arranged in columns that should be organized into a single column.
-
Multiple Columns, no Table - Enable this setting if your pages contain text in columns that should be kept in separate columns, similar to the original layout. If table-like data is detected, it will be placed in columns, not in a gridded table.
-
Single Column with Table - Enable this setting if your pages contain only one column of text and a table.
-
Spreadsheet - Enable this setting if your pages contain a table to be exported to a spreadsheet program or be treated as a table.
-
Form - Enable this setting if your pages contain forms. Form objects and elements will be detected.
-
Legal Pleading - Enable this setting if your pages contain legal pleading numbers. Once enabled, the following options will be available:
-
Remove legal pleading numbers - Choose this option to remove all pleading numbers from incoming documents.
-
Retain legal pleading numbers - Choose this option to keep all pleading numbers in incoming documents. In this case, the numbers will be visible, editable, and searchable.
-
-
Optimize the OCR process for:
-
Fast recognition - Enable this setting to optimize the recognition process for speed. Although this setting produces the least accurate results, it can be useful when you know that your incoming documents are of good quality and can yield acceptable, accurate results. With this setting enabled, advanced formatting, such as colored text/background and inverted text, may not be retained.
-
Mid-level accuracy/speed recognition - Enable this setting for a balance between speedy processing and accurate results.
-
Most accurate recognition - Enable this setting to optimize the recognition process for accuracy.
-
-
Specify maximum size of the images allowed - Set a width and height limit (in pixels) for incoming images. All incoming images that exceed those specified values will not be processed. The default value is 8400 x 8400 pixels.
-
Timeout - Specify the time in seconds you want to elapse before the OCR recognition process times out.
Output Tab
You can also specify settings for the output of the OCR process. Note that the Output tab appears only for nodes that convert documents to another format. In addition, if you access this window from the Advanced OCR node and have specified Original Document + Metadata as the Output option, this tab does not appear.
Note: The set of options available on this tab is determined by the OCR engine, based on the functional capabilities of the engine. If an option does not appear in the tab, it is not supported by the OCR engine. The illustrations below show the options available for the OmniPage and Tesseract OCR engines. All options are described in the section below the illustrations.
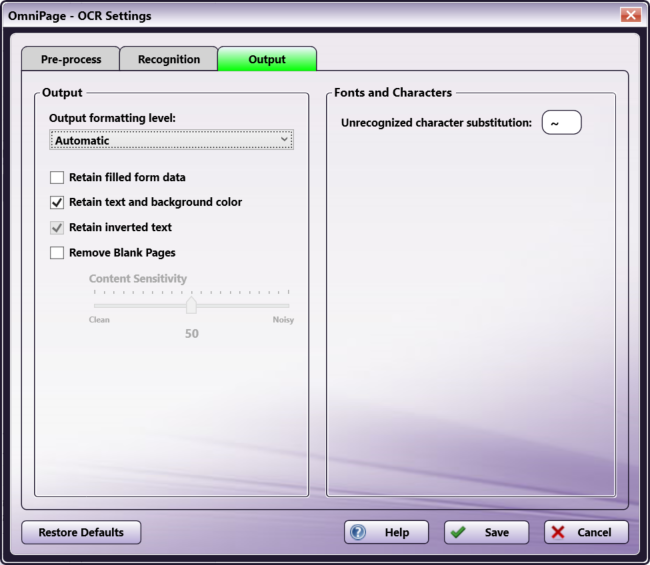
OmniPage Options
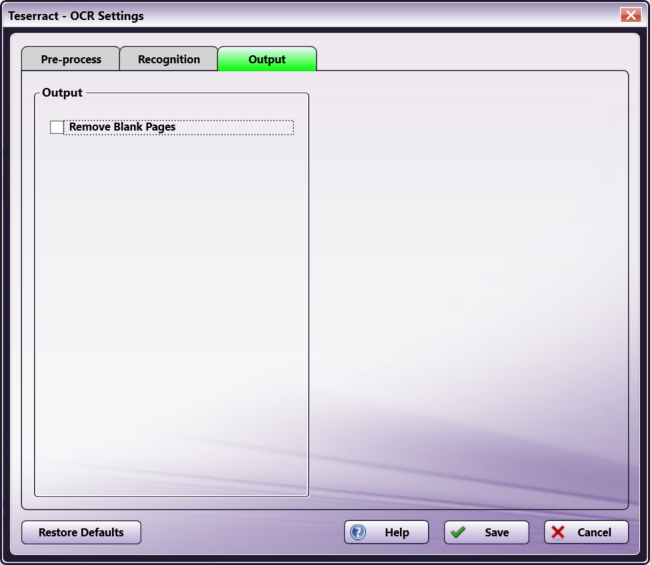
Tesseract Options
Output
-
Output formatting level
-
Automatic - When this setting is enabled, the OCR engine will automatically decide which output format to use based on the layout either specified or detected.
-
Plain Text - When this setting is enabled, the OCR process will output plain, left-aligned text in a single column.
-
Formatted Text - When this setting is enabled, the OCR process will output text with font and paragraph styling, along with graphics and tables.
Note: When saving as an Excel file, each detected table or spreadsheet in a document will be saved in a separate worksheet.
-
True Page - When this setting is enabled, the original layout of the pages, including columns, will be retained on output, using text, picture and table boxes and frames.
-
Flowing Page - When this setting is enabled, the original layout of the pages, including columns, will be retained on output using, wherever possible, columns and indent settings (instead of text boxes or frames). Text flows from one column to the other.
-
Spreadsheet - When this setting is enabled, the results are output in tabular form, suitable for use in spreadsheet applications. Each page is placed in a separate worksheet.
-
-
Retain filled form data - When this setting is enabled, filled form data will be retained during the conversion process. This box is unchecked by default.
-
Retain text and background color - When this setting is enabled, colored text and backgrounds will be detected and available for output. Disable this setting if you want color pictures in the document but not colored text/backgrounds. This box is checked by default.
-
Retain inverted text - When this setting is enabled, inverted text (white or pale letters on a black/dark background) is maintained on output. Disable this setting to transform inverted text to normal text. This option is unavailable if the Optimize the OCR process for Fast recognition option is set.
-
Remove Blank Pages - When this setting is enabled, blank pages will not be included in the output file. This box is unchecked by default.
- Content Sensitivity - Specify the threshold for sensitivity to marks and blemishes on blank pages.
- Clean - Move the slider towards Clean (100) to increase the sensitivity threshold.
- Noisy - Move the slider towards Noisy (0) to decrease the sensitivity threshold.
- Content Sensitivity - Specify the threshold for sensitivity to marks and blemishes on blank pages.
Output Formats/Types Supported by Dispatcher Phoenix
| Output Format/Type | Plain text | Formatted text | Spread Sheet | True Page | Flowing Page |
|---|---|---|---|---|---|
| eBook | YES | YES | NO | NO | NO |
| Microsoft Excel | YES | YES | YES | NO | NO |
| Microsoft PowerPoint / Microsoft Publisher | YES | YES | NO | NO | NO |
| Microsoft Word | YES | YES | NO | YES | YES |
| NO | NO | NO | YES | NO | |
| PDF – Edited | YES | YES | NO | YES | NO |
| PDF with image on text or image substitutes | NO | NO | NO | YES | NO |
| RTF Word 2000 | YES | YES | NO | YES | YES |
| WordPad | YES | YES | NO | NO | NO |
| WordPerfect 9, 10 | YES | YES | NO | YES | YES |
| XML Paper Specification (XPS) | NO | NO | NO | YES | NO |
Note: The default option for all output formats is “Automatic”.
Fonts and Characters
Unrecognized character substitution - By default, unrecognizable characters found by the OCR engine will be represented in the output by a red tilde character (~). For example, if the OCR process could not recognize ‘j’ in ‘reject,’ the output would be: re~ect. You can specify your own character to use in this field.
Barcode Engines
Barcode recognition is driven by a barcode engine. Dispatcher Phoenix currently supports the following barcode engines:
ZXing Nodes
The following nodes support the ZXing barcode engine:
- 2D Barcode Processing - The 2D Barcode Processing node is included in the Dispatcher Phoenix base license with support for the ZXing engine. Support for the OmniPage can be purchased separately. Note that Advanced Settings for the ZXing engine are detailed below.
- Barcode Processing - The Barcode Processing node is included in the Dispatcher Phoenix base license with support for the ZXing engine. Support for the OmniPage can be purchased separately. Note that Advanced Settings for the ZXing engine are detailed below.
Advanced Settings for ZXing

Advanced options for the ZXing Barcode Engine include the following:
- Optimize the Barcode Scanning process for: - This setting controls how the engine scans for barcodes.
- Accuracy - Enable this setting to optimize the recognition process for accuracy.
- Performance - Enable this setting to optimize the recognition process for speed. Although this setting potentially produces less accurate results, it can be useful when you know that your incoming documents are of good quality and can yield acceptable, accurate results.
- Zone Rotation to Aid in Barcode Detection - Before scanning for barcodes, the application tries to detect and correctly orient zones for barcode detection. If you already know the exact misalignment of incoming files and want to speed up processing time by avoiding this auto-detection process, you can choose specific options here.
- Rotate zones 90, 180, and 270 degrees during scan - When this setting is enabled, the orientation of a zone is detected and improperly oriented zone images are automatically rotated (by 90, 180, or 270 degrees) before OCR takes place. This enabled option is the default value for rotation and mirroring.
- Do not rotate zones - When this setting is enabled, zones are not rotated.
- Zone inversion to Aid in Barcode Detection - Before scanning for barcodes, barcode zones that are detected with white text against a dark background can be temporarily inverted during the preparation process to increase the accuracy of the OCR results.
- Invert zones during scan - When this setting is enabled, the need for color inversion is detected and inversion is performed on the zone during pre-processing. This enabled option is the default value.
- Do not invert zones - When this setting is enabled, zones are not inverted before the OCR process begins. Note that the accuracy of the OCR results may be affected with this option enabled.
- Downscale Zones to Aid in Processing Speed - This setting controls how the engine scans for barcodes on large files.
- Downscale zones before attempting barcode detection - When this setting is enabled, the engine will attempt to temporarily downsize the zone to detect barcodes. This can lead to performance improvements.
- Do not downscale zones - When this setting is enabled, zones are not downscaled before scanning.