Tabs: Predefined

Note: This node works with PDF files (version 1.3 or later).
The Tabs: Predefined Node parses all the pages of an input PDF file, and then searches for tab pages. The page numbers of sheets that have tab pages are saved in the metadata and carried with the PDF file to the next node of the workflow.
This node supports three metadata key-value pairs. These key-value pairs are set (predefined) in the PDF prior to being input to this mode:
-
job:tab.paper.w (Optional) – The Paper Width of the tab sheets.
-
job:tab.paper.h (Optional) – The Paper Height of the tab sheets. Paper Width and Paper Height must be set together. If they are not, the Tab Paper Size applied is based on the size of the first page size of the PDF file.
-
Job:tab.paperweight (Optional) – The Paper Weight of the tab sheets. If the Tab Paper Weight metadata is invalid then the Tabs: Predefined Node displays a message in the Activity Log of the workflow and moves the PDF document to the node’s Error folder.
Note: This Help file contains detailed information about supported Tab Paper Weights. Refer to Job Ticket Metadata. When launched, the Metadata Browser window displays the pre-defined Job Ticket Metadata, the system-defined variables (such as Date, File, System and User info), and the metadata values from the active node.
Note: The Orientation of the Tab Sheet is based on the first page of the input PDF. When the first page of the input PDF is Portrait, the tab sheet inserted will be Portrait and the value entered in the Tab Order field is applied. When the first page of the input PDF is Landscape, the tab sheet inserted will be Landscape and the value entered in the Tab Order field is applied.
Using the Tabs: Predefined Node
Add the Tabs: Predefined Node to the workflow by dragging the node’s icon onto the Workflow Builder canvas, and then double-clicking on the icon to open the Tabs: Predefined Node’s window:
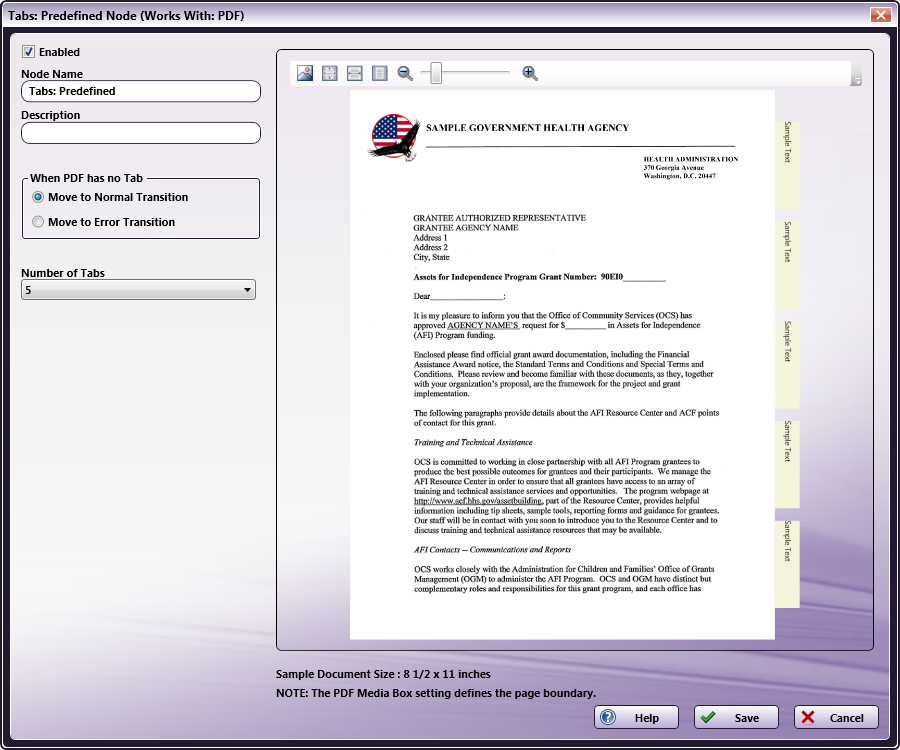
Specify the Tab and Text properties in this window. The Preview panel provides a real-time image of how the selected settings will look on the printed version of the document.
-
Select the Enabled checkbox so that the process will run. When unchecked, this process is ignored. Documents pass through as if the node were not present (i.e., continue along the default or positive path). Note that a disabled node will not check for logic or error conditions.
-
In the Node Name field, enter a meaningful name for the Tabs: Predefined Node.
-
In the Description field, enter a description for the Tabs: Predefined Node.This is not required, but can be helpful with multiple collection points. If the description is long, hover the mouse over the field to read its entire contents.
-
In the Number of Tabs field, select the number of tabs from the drop-down option.
-
Select the Save button to apply the Tabs: Predefined settings. Select the Cancel button to exit the window without saving any changes.
-
Select the Help button to access online help.
Note: Tab Page Size is determined by the first page of the submitted PDF file. The following sizes are supported: A3, A4, A5, B4, B5, Half Letter, Letter, Tabloid. If the first page doesn’t match any of the supported paper sizes, then a “Tab Sheet is not supported” error message is displayed and the PDF file is moved to the Error Folder.
Select Transition
If the Tabs: Predefined Node receives a PDF files that does not contain Tabs, use this setting to tell the workflow what to do with the file:

- Move to Normal Transition: even without Tabs, the file is sent to the next node in the workflow and processed normally.
- Move to Error Transition: Because the Tab application is integral to the processing of the job, files that lack Tabs are moved to an Error folder and must be processed manually.
Number of Tabs
Use this drop-down to specify the number of tabs in the document. The value entered here will be converted to metadata. If additional Tab page settings are included, these settings are also added to the metadata. This metadata can then be used in the AccurioPro Conductor Connector Node.
A job can enter this node with the Number of Tabs value already specified. If that happens, the value is identified using the metadata key {job:tab.amount}. When a job that includes this metadata key enters the Tabs: Predefined Node, any UI values set using this option are ignored and will be overwritten by the metadata value.
Tool Bar
The Toolbar is at the top of the window. Use it to customize the Preview.
| Tool Bar Icons | Description |
|---|---|
 |
Image icon. Click on this icon to change the sample preview image. Only PNG, JPEG and PDF formats are supported. Supported image display sizes are: A3,A4,A5,B4,B5, Half Letter,Letter, and Tabloid. |
 |
Actual Size icon. Click on this icon to revert the preview sample document to its original size. |
 |
Fit to Width icon. Click on this icon to stretch the sample document to fit the width of the Preview area. |
 |
Whole Page icon. Click on this icon and the sample document fills the Preview area. |
 |
Zoom controls. Use either the magnifying glass icons or the sliding bar to zoom in and out of the Preview area. |
Sample of a Tabs: Predefined Workflow
The purpose of this workflow is to receive XML files, parse the job ticket into XML metadata, extract the predefined tab information, save the extracted information to metadata, and then send the modified document and the extracted tab information to the AccurioPro Conductor for printing. When the job prints, the tabs are included.
Note: This node produces metadata output with key name as “Job”.
A detailed explanation of each node of the workflow follows:
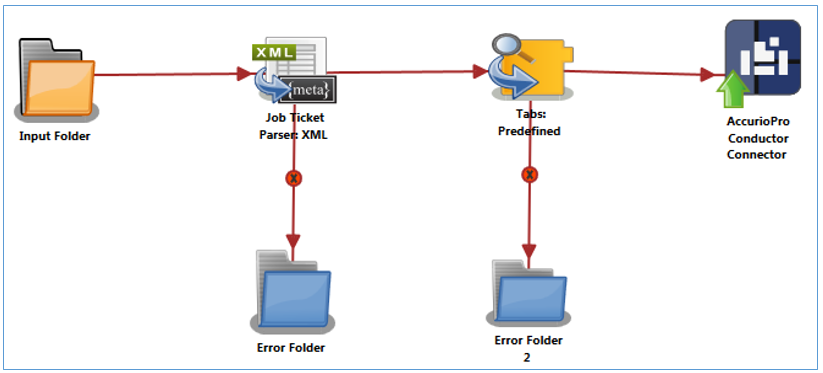
Input Folder Node: Configure the Input Folder to collect XML job tickets and forward them to the Job Ticket Parser: XML node in the workflow. The forwarded XML job ticket files contain the tab information. Below is a sample job ticket that contains the tab information:
<Ticket>
<Tab>
<Width>9</Width>
<Height>11</Height>
<Weight>40</Weight>
</Tab>
<Paper>
<Unit>inch</Unit>
</Paper>
<File>file</File>
<Src>C:\\test files\\Letter_Tab.pdf</Src>
</Ticket>
Job Ticket Parser: XML Node: If the document is formatted as XML, the XML information is converted to job ticket metadata and sent forward in the workflow. If a document is not formatted as XML, that document is moved to the Error Folder.
Use this process to map an XML job ticket:
-
Open a text editor then copy the sample XML code noted is the sample job ticket above.
-
The Source Path <Src> noted in the sample job ticket needs to be changed so that the path is valid.
-
Save locally as XML_Tabs_Pre.xml.
-
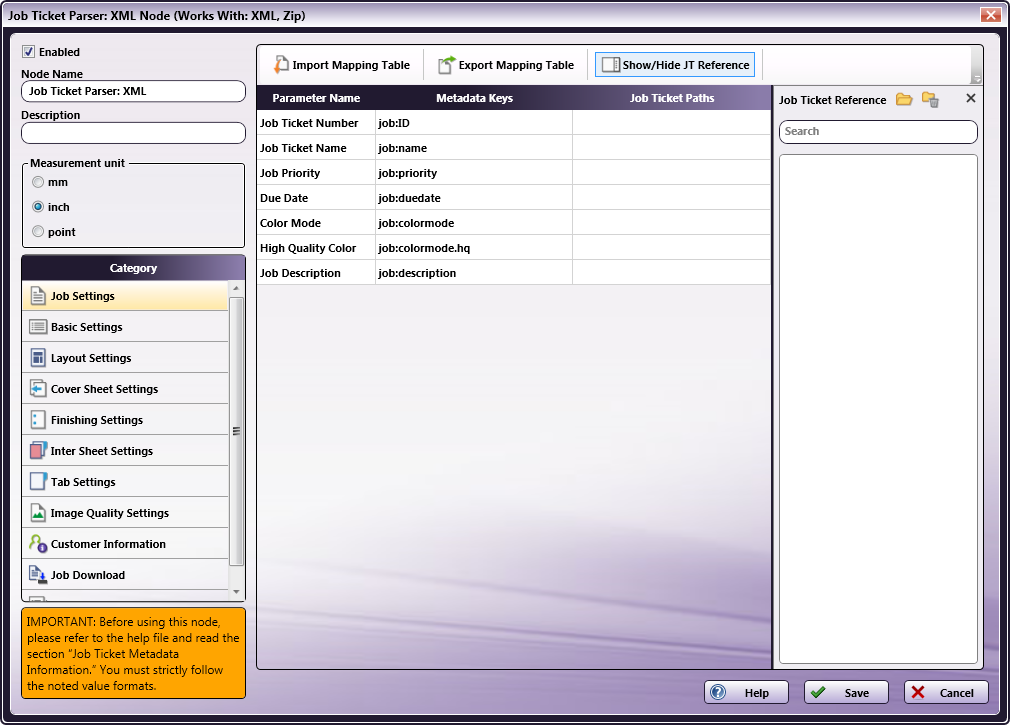
Double-click on the Job Ticket Parser: XML Node. The settings screen opens.
-
In the left panel, set the following values:
- Enable checkbox: Select to enable the node to accept jobs
- Node Name: Assign a name value to the node in the text field
- Measurement unit: Select the radio button that corresponds to the measurement unit required for the node
-
In the Job Ticket Reference panel(far-right), locate the Open icon:
-
Click the icon.On the screen that opens, navigate to and select the file saved in Step 3 above (XML_Tabs_Pre.xml).
-
When the file opens, its contents (or XPaths) display in the Job Ticket Reference panel (far-right).
-
In the Category panel (far-left), click on Basic Settings. The Parameter Name, Metadata Keys, and Job Ticket Paths columns display in the main panel:
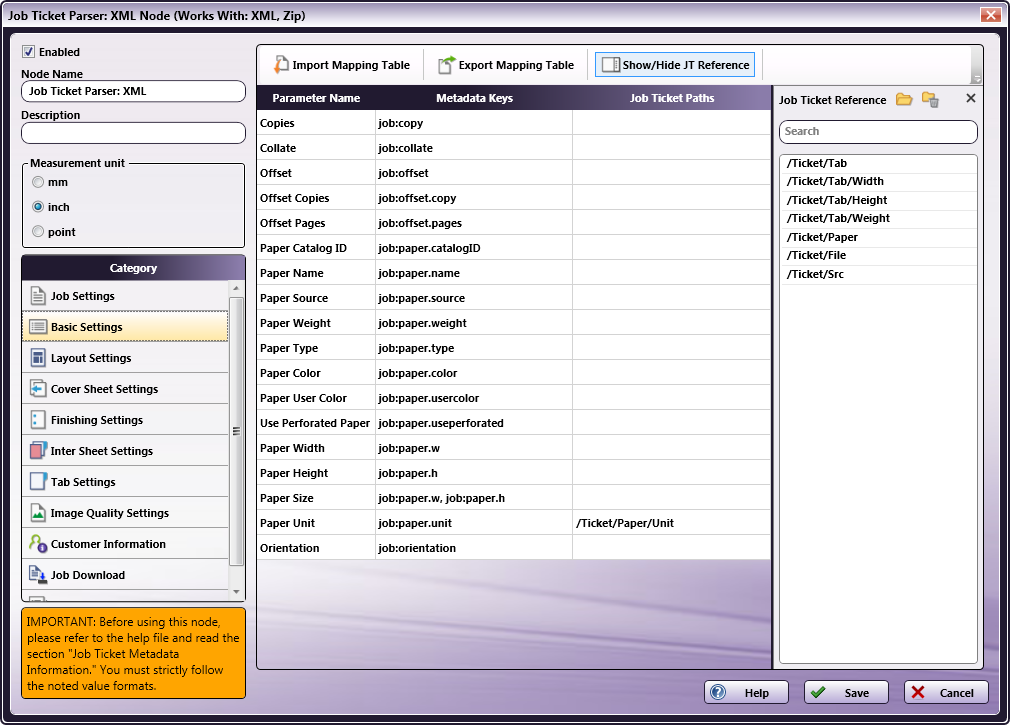
-
From the Job Ticket Reference panel, drag-and-drop /Ticket/Paper/Unit to the Job Ticket Paths cell of the Paper Unit row.
-
In the Category panel (far-left), click on Tab Settings. The Parameter Name, Metadata Keys, and Job Ticket Paths columns display in the main panel:
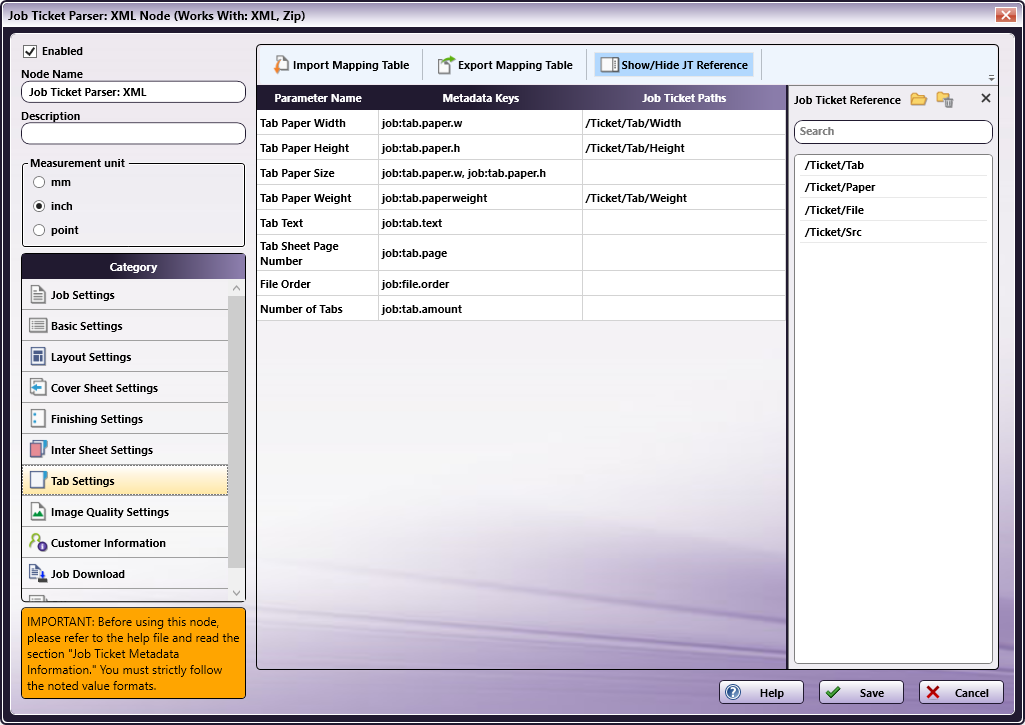
-
Values from the Job Ticket Reference panel need to be moved to the Job Tickets Paths column, to the open cell that corresponds to the value’s Parameter Name.
-
Drag-and-drop /Ticket/Tab/Weight to the Job Ticket Paths cell of the Tab Paper Weight row.
-
Drag-and-drop /Ticket/Tab/Width to the Job Ticket Paths cell of the Tab Paper Width row.
-
Drag-and-drop /Ticket/Tab/Height to the Job Ticket Paths cell of the Tab Paper Height row.
-
In the Category panel (far-left), click the Job Download option. The Documentation Source and Job Ticket Path: File Type fields and the Retrieve Print File Option checkboxes display in the main panel:
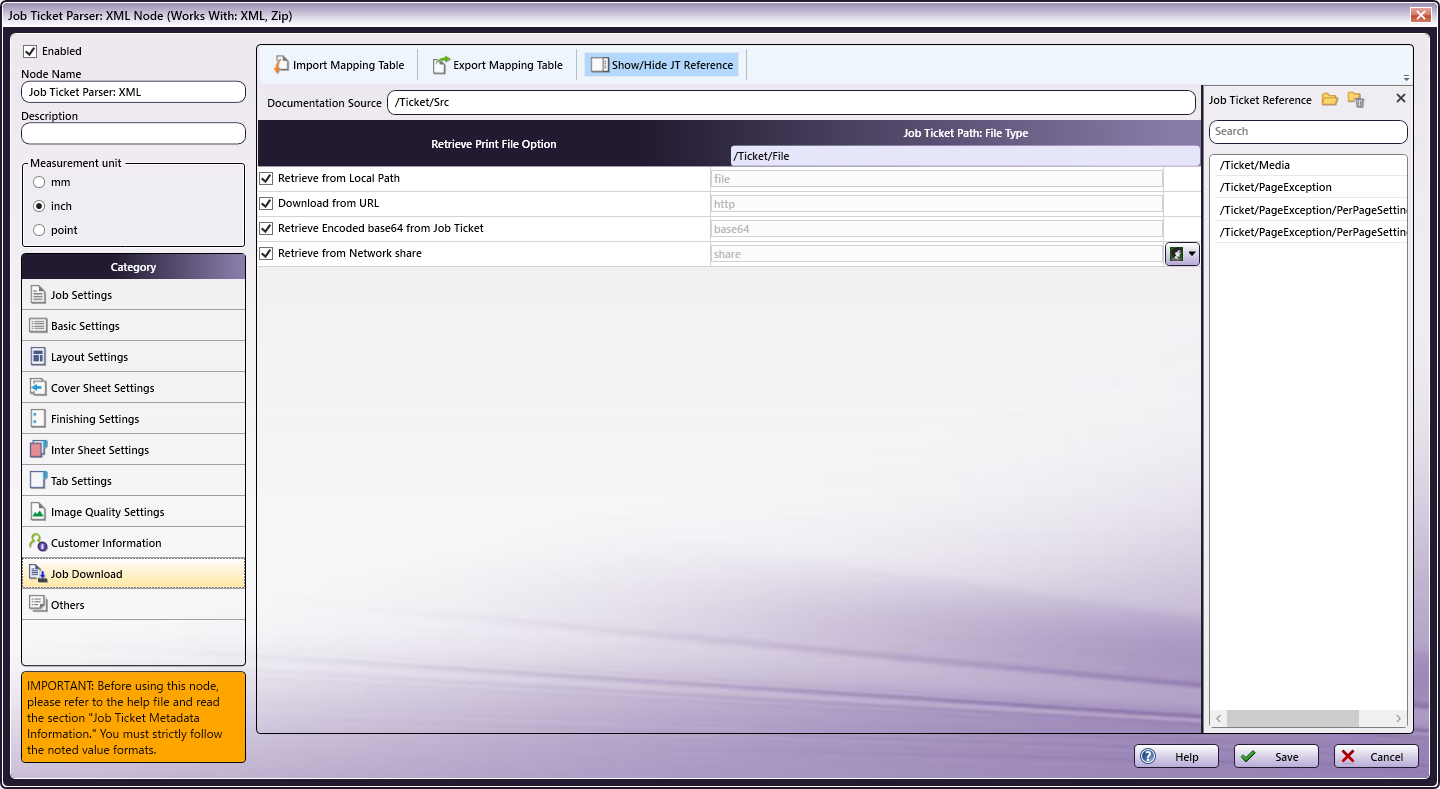
-
In the Retrieve from File Option column, select the checkboxes of all four options: Retrieve from Local Path, Download from URL, Retrieve Encoded base64 from Job Ticket, and Retrieve from Network share.
-
From the Job Ticket Reference panel, drag-and-drop /Ticket/Src to the Documentation Source field.
-
From the Job Ticket Reference panel, drag-and-drop /Ticket/File to the Job Ticket Path: File Type field.
-
Once these actions are completed, the screen will appear as shown in the image above.
-
Click Save to apply the changes to the node.
Tabs: Predefined Node: The Tab Predefined Node will parse all tab pages in the input document based on the tab page settings, and then add the parsed tab page information to the metadata.
The Tabs: Predefined Node can be connected to the rest of the nodes via Yes and No transitions.
- Regardless of whether a document contains Tab pages, the Move to Normal Transition radio button can be selected to route all documents forward in the workflow.
- If a document does not have Tab pages, the Move to Error Transition radio button can be selected to route only documents without Tabs to an Error Folder 2. Documents with Tabs move forward in the workflow.
AccurioPro Conductor Connector Node: The document (and its Tabs) are sent to the AccurioPro Conductor Connector Node. From there, the documents may be printed.