HL7 Parser

HL7 (Health Level 7) is a standard of communication across the Healthcare market. The HL7 Parser allows Dispatcher Phoenix customers to parse HL7 messages into document metadata for use within Dispatcher Phoenix and extracts documents imbedded within HL7 messages. For more information about HL7 messages, see the Overview of HL7 or visit https://hl7-definition.caristix.com/v2/HL7v2.8/Segments/.
Important! The HL7 Parser node is configured to best parse HL7 v2.8 messages, but is capable of parsing any HL7 v2.x messages. When parsing older versions of HL7 v2.x, parsed data may not appear as expected, including data being parsed with slightly different segment names, parsed in separate or combined subsegments, etc. For more information about parsing older versions of HL7 v2.x, contact Dispatcher Phoenix Engineering Services.
Configuring the HL7 Parser
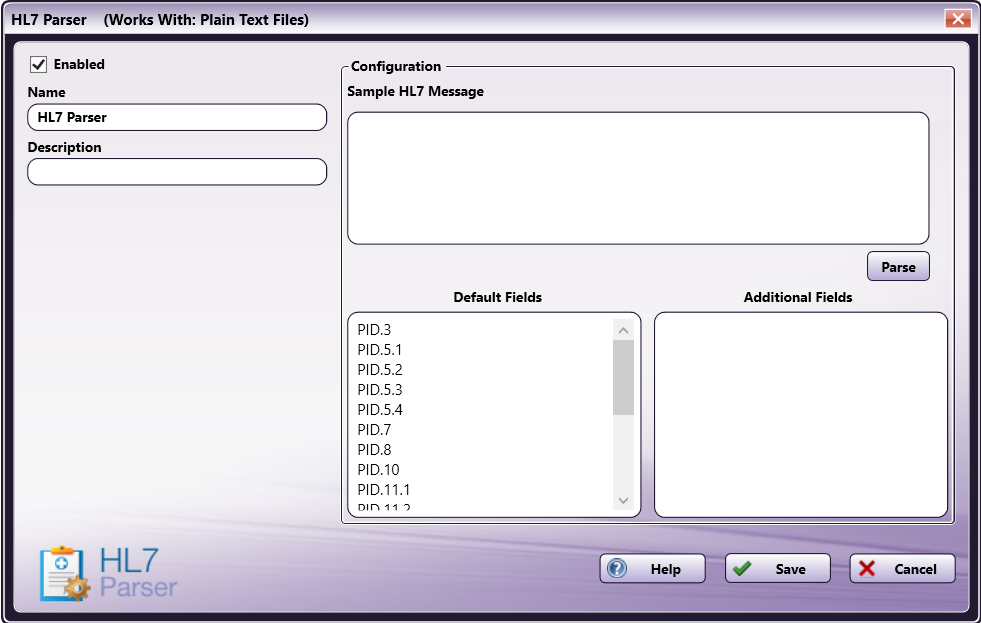
To open the HL7 Parser node’s properties window, add the Process node called “HL7 Parser” to your workflow and double-click on it.
-
Enabled - To enable this node in the current workflow, ensure the Enabled checkbox is clicked. By default, nodes are enabled upon creation. If you disable the node, the workflow will ignore it, and documents pass through as if the node was not present. Note that a disabled node does not check for logic or error conditions.
-
Node Name - The node name defaults into this field. This name appears in the workflow below the node icon. Use this field to specify a meaningful name for the node that indicates its use in the workflow.
-
Node Description - Enter an optional description for this node. A description can help you remember the purpose of the node in the workflow or distinguish nodes from each other. If the description is long, you can hover the mouse over the field to read its entire contents.
Buttons
- Help - To access Dispatcher Phoenix Online Help, click this button.
- Cancel - To exit the window without saving any changes, click this button.
- Save - To preserve your node definition and exit the window, click this button.
Sample HL7 Message
The HL7 Parser node allows you to input a sample HL7 message to determine which HL7 message segments are typically used by your organization. To parse a sample message, do the following:
-
Enter or paste a copied HL7 message into the Sample HL7 Message field.
-
Select the “Parse” button.
-
The HL7 Parser node will then separate all HL7 message segments and subsegments and compare them to the Default Fields. Any Additional Fields will automatically populate in the Additional Fields area, as in the following illustration:
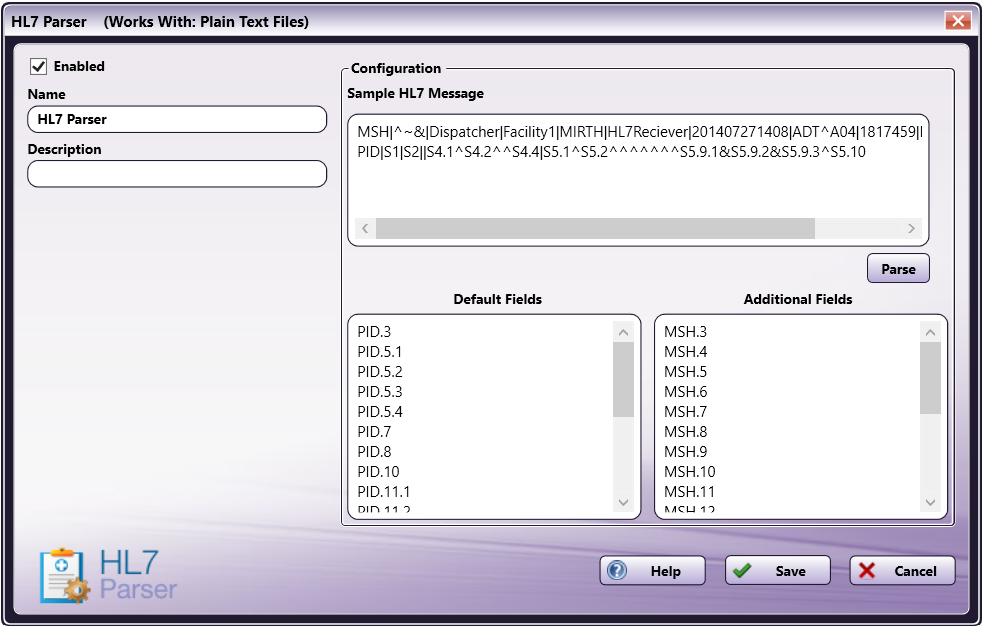
Important! To maintain security and compliance, the Sample HL7 Message section automatically deletes any information in that area after the node is closed. This information in this section is not saved in any way, even if you select the Save button.
Notes:
- The HL7 Parser will not parse any HL7 messages that do not contain the MSH segment at the beginning of the message.
- When using the Sample HL7 Message parser to add segments to the Additional Fields area, the node will always add to the segments already defined. It will not delete existing entries.
Default Fields
The HL7 Parser is configured to automatically parse several Default Fields of the HL7 message, which represent the most commonly-used segments of typical HL7 messages. These are listed in the bottom left-hand box and include:
| ID | Description of Patient Information |
|---|---|
| PID.3 | Patient identifier list |
| PID.5.1 | Family name |
| PID.5.2 | Given name |
| PID.5.3 | Second and further given names or initials thereof |
| PID.5.4 | Suffix |
| PID.7 | Date and time of birth |
| PID.8 | Administrative Sex |
| PID.10 | Race |
| PID.11.1 | Street address |
| PID.11.2 | Other designation |
| PID.11.3 | City |
| PID.11.4 | State or province |
| PID.11.5 | Zip or postal code |
| PID.11.6 | Country |
| PID.13 | Phone number - Home |
| PID.15 | Primary language |
| PID.17 | Religion |
| PID.19 | SSN - Patient |
| PID.22 | Ethnic group |
Additional Fields
Additional Fields of the HL7 message can be added to the node configuration, by either using the Sample HL7 Message parsing feature described above or by typing them manually into the bottom right-hand box, labeled Additional Fields. Note that any Additional Fields can either be entered separated by a space or on their own line for the workflow to pass validation. Note that segments separated by a space will be placed on their own line after the node is saved.
For a segment with subsegments, the user has the ability to enter the top-level segment without specifying which subsegments to parse. In this case, the metadata generated will include ALL the data contained in each subsegment. For example, the user could enter “ABS.1” in the Additional Fields area. The metadata for “ABS.1” would include any values detected for “ABS.1.1” through “ABS.1.25”, including any further subsegments, such as “ABS.1.23.1” through “ABS.1.23.22”.
Notes:
-
The HL7 Parser does not perform any data validation on parsed data. For example, “PID.7” refers to the patient date of birth. In the HL7 message, a birthdate of January 15, 2087 is written as “19870115”. If the metadata needs to be converted to a different format, a Metadata Scripting node or similar can be used in the workflow.
-
If the HL7 Parser is configured to parse information from an HL7 segment that does not have any data, the node will create metadata with a null value.
Important! HL7 segments must be in the format of XXX.#.#. Other formats, such as XXX-#.# will produce an error.
Extracting Documents from HL7 Messages
The HL7 Parser is capable of extracting imbedded documents from the HL7 message. These documents typically are located in the OBX.5 segment. The node will not parse the OBX.5 segment into metadata, but will instead take the information contained in this segment and create a document based on that information, which can be used later in the workflow. The type of document is determined by the data contained in the OBX.2 and OBX.5 segments.
Note: Because the HL7 Parser converts the OBX.5 segment into a document, it cannot be used for metadata. If the OBX.5 segment is added to the Additional Fields area, the node will not pass validation and the workflow will produce an error and not run.
Overview of HL7
HL7 is an international standard for transferring medical data between disparate healthcare systems. An HL7 message is comprised of one-character delimiters that separate the individual parts of the message.
| Delimiters: | |
|---|---|
| 0x0D | Marks the end of each segment |
| ^ | Sub-composite delimiter |
| & | Sub-sub-composite delimiter |
| - | Separates repeating fields |
| \ | Escape character |
Sample HL7 Message
Below is an example of a an HL7 message:
MSH|^~&|Dispatcher|Facility1|MIRTH|HL7Reciever|201407271408|ADT^A04|1817459|D|2.8|123456||AL
PID|S1|S2||S4.1^S4.2^^S4.4|S5.1^S5.2^^^^^^^S5.9.1&S5.9.2&S5.9.3^S5.10
In this message, the HL7 Parser will extract the following information:
- PID.1 will produce a metadata value of “S1”
- PID.4 will produce a metadata value of “S4.1^S4.2^^S4.4”
- PID.4.2 will produce a metadata value of “S4.2”
- PID.5 will produce a metadata value of “S5.1^S5.2^^^^^^^S5.9.1&S5.9.2&S5.9.3^S5.10”
- PID.5.9 will produce a metadata value of “S5.9.1&S5.9.2&S5.9.3”
- PID.5.9.3 will produce a metadata value of “S5.9.3”